
OpenStack Networking - FlatManager and FlatDHCPManager
Over time, networking in OpenStack has been evolving from a simple, barely usable model, to one that aims to support full customer isolation. To address different user needs, OpenStack comes with a handful of "network managers". A network manager defines the network topology for a given OpenStack deployment. As of the current stable "Essex" release of OpenStack, one can choose from three different types of network managers: FlatManager, FlatDHCPManager, VlanManager. I'll discuss the first two of them here.
FlatManager and FlatDHCPManager have lots in common. They both rely on the concept of bridged networking, with a single bridge device. Let's consider her the example of a multi-host network; we'll look at a single-host use case in a subsequent post.
For each compute node, there is a single virtual bridge created, the name of which is specified in the Nova configuration file using this option:
flat_network_bridge=br100
All the VMs spawned by OpenStack get attached to this dedicated bridge.
[caption id="attachment_82804" align="aligncenter" width="255"]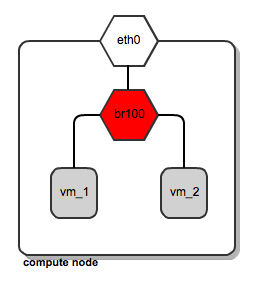 Network bridging on OpenStack compute node[/caption]
Network bridging on OpenStack compute node[/caption]
This approach (single bridge per compute node) suffers from a common known limitation of bridged networking: a linux bridge can be attached only to a signle physical interface on the host machine (we could get away with VLAN interfaces here, but this is not supported by FlatDHCPManager and FlatManager). Because of this, there is no L2 isolation between hosts. They all share the same ARP broadcast domain.
The idea behind FlatManager and FlatDHCPManager is to have one "flat" IP address pool defined throughout the cluster. This address space is shared among all user instances, regardless of which tenant they belong to. Each tenant is free to grab whatever address is available in the pool.
FlatManager
FlatManager provides the most primitive set of operations. Its role boils down just to attaching the instance to the bridge on the compute node. By default, it does no IP configuration of the instance. This task is left for the systems administrator and can be done using some external DHCP server or other means.
[caption id="attachment_82853" align="aligncenter" width="494"] FlatManager network topology[/caption]
FlatManager network topology[/caption]
FlatDHCPManager
FlatDHCPManager plugs a given instance into the bridge, and on top of that provides a DHCP server to boot up from.
On each compute node:
- the network bridge is given an address from the "flat" IP pool
- a dnsmasq DHCP server process is spawned and listens on the bridge interface IP
- the bridge acts as the default gateway for all the instances running on the given compute node
[caption id="attachment_83167" align="aligncenter" width="717"]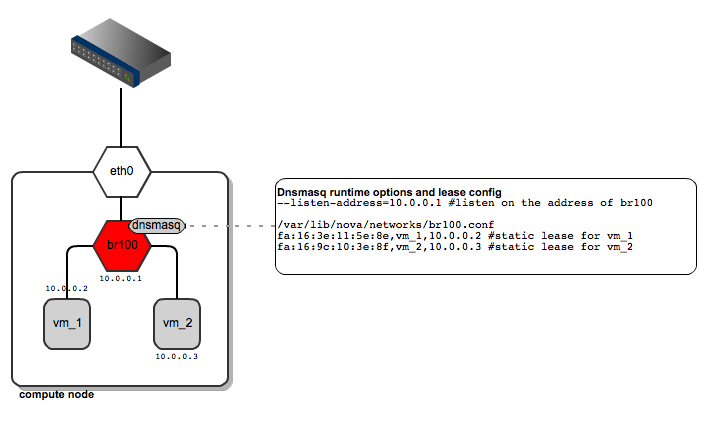 FlatDHCPManager - network topology[/caption]
FlatDHCPManager - network topology[/caption]
As for dnsmasq, FlatDHCPManager creates a static lease file per compute node to guarantee the same IP address for the instance over time. The lease file is constructed based on instance data from the Nova database, namely MAC, IP and hostname. The dnsmasq server is supposed to hand out addresses only to instances running locally on the compute node. To achieve this, instance data to be put into DHCP lease file are filtered by the 'host' field from the 'instances' table. Also, the default gateway option in dnsmasq is set to the bridge's IP address. On the diagram below you san see that it will be given a different default gateway depending on which compute node the instance lands.
[caption id="attachment_82803" align="aligncenter" width="515"]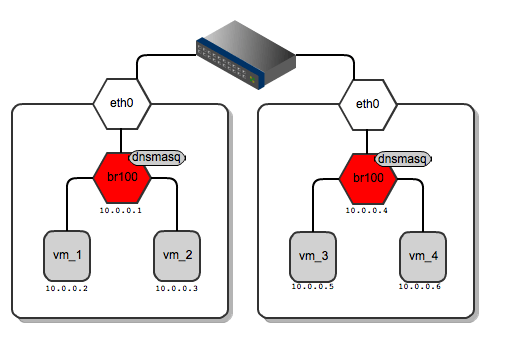 Network gateways for instances running on different compute nodes[/caption]
Network gateways for instances running on different compute nodes[/caption]
Below I've shown the routing table from vm_1 and for vm_3 – each of them has a different default gateway:
root@vm_1:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.1 0.0.0.0 UG 0 0 0 eth0
root@vm_3:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.0.4 0.0.0.0 UG 0 0 0 eth0
By default, all the VMs in the "flat" network can see one another regardless of which tenant they belong to. One can enforce instance isolation by applying the following flag in nova.conf:
allow_same_net_traffic=False
This configures IPtables policies to prevent any traffic between instances (even inside the same tenant), unless it is unblocked in a security group.
From practical standpoint, "flat" managers seem to be usable for homogenous, relatively small, internal corporate clouds where there are no tenants at all, or their number is very limited. Typically, the usage scenario will be a dynamically scaled web server farm or an HPC cluster. For this purpose it is usually sufficient to have a single IP address space where IP address management is offloaded to some central DHCP server or is managed in a simple way by OpenStack's dnsmasq. On the other hand, flat networking can struggle with scalability, as all the instances share the same L2 broadcast domain.
These issues (scalability + multitenancy) are in some ways addressed by VlanManager, which will be covered in an upcoming blog posts.

