
Creating an RPC over RabbitMQ PoC in OpenStack: What is Tavrida?
- April 12, 2016
In this world of microservices, RPC is becoming more important than ever, and perhaps nowhere is that more true than in OpenStack, which uses messaging at its core. Tavrida is a lightweight library for RPC over RabbitMQ, created to enable developers to build easily and quickly build small services that asynchronously intercommunicate via RabbitMQ using the RPC interface. Tavrida also allows services to execute publications and establish subscriptions.
The “nameko” library implements message handling using callbacks, which was a problem because we were trying to create request handlers that were as pure as it's possible. Callbacks are objects that exist in the process' memory during the process' lifetime, and therefore they can be modified. When you have complicated logic, a big project and a large team (and especially a distributed team) it's impossible to be absolutely certain of code modifications that are happening in run-time.
Instead, we wanted a library in which controllers and handlers are created for each request. We also wanted to route requests based on service and handler names, as opposed to objects in memory.
So what to do? We decided that we'd experiment with a new way of doing things by creating Tavrida, a proof of concept for RPC over RabbitMQ that satisfies our requirements. Once we've got things working as we think the should, we can then look at how this functionality can be integrated with existing OpenStack code.
Tavrida is also useful if you want to use asynchronous communications between your services. This approach is better in situations in which execution of some operations takes a long time and you don't want to block your entire application or system until the operation finishes.
In our case, we use Tavrida on an OpenStack project we're building for a large telco customer, where we have a microservices architecture and long-running operations such as virtual machine start/stop/reboots or configuration of remote network devices.
A service is actually a class that includes request/response/error handlers, and also is able to subscribe for notifications. Each handler method is mapped to an entry point — the point that could be considered as an address -- the remote method name for request/response/error, or as a topic for publications. This entry point is the point that is exposed to other services. It consists of service name and method name.
So when the message is routed to the handler according to its entry point, Tavrisa executes custom handling logic. The first two parameters that are passed to each handler are the message and proxy objects. All following parameters are the generic RPC method parameters. For example:
Using the proxy object it's possible to make calls to another remote service method or to publish a notification. The entry point of the handler method from which you execute the call to the remote service is considered as the source of the outgoing message, with the name of the called service and method as the destination entry point.
The same logic works for the response and error messages. On the other hand, notifications use the source entry point value as the topic (but still send it in the «source» header). Other services can use this entry point to subscribe for these notifications. For example:
The response is returned by the handler via the instantiating response object, or just as a dict that will be converted to a response object automatically. For example:
To register the remote or local service, you call the corresponding method of the discovery object. The discovery object is an object that holds the «service_name»: «service_exchange» mappings and enables the local service to send messages to the correct exchange.
All this means that for one service to intercommunicate with one or more others, you must instantiate the discovery object, register the remote or local services and bind the discovery object to the given service before starting the server.
Let's take a look at the code example:
Exchanges are created according to the registrations in the discovery object. That means that you don't have to think about the manual creation of AMQP structures: Tavrida will take care of it; you just need to configure it correctly.
Each service has it's own queue. All messages that are meant for the service are delivered to this queue.
Each service queue is bound to the service's first (required) exchange with binding keys based on service name. Optionally, it may be bound to a second (optional) exchange of a remote service from which to receive notifications. In the latter case the remote (publisher) entry point will be used as the basis for the binding key.
While preparing this article, I ran a few performance tests on my laptop, an Intel® Core™ i7-3630QM CPU @ 2.40GHz × 8 with just 8GB RAM. The load was constant during each test, and each service was instantiated only once, resulting in a single process for each service.
Here are the results:


You'll notice that as we get more complex, the overall number of messages handled goes down. That's because in this case we have only one service, so all messages, regardless of type, are transferred to that one service’s queue. Thus requests to service A and responses from B to A are rivals. If service A gets less fewer requests it is can handle more responses, and vise versa.
So what do you think? Is this useful to you? If so, we'd love for you to join us in making Tavrida better. Let us know in the comments what you'd like to see!
Wait a minute, doesn't OpenStack already do messaging?
In the early stages of this project, we looked at the the “oslo.messaging” and “nameko” libraries. We found that “oslo.messaging” doesn't handle subscriptions, which was a problem right off the bat, but the "nameko" situation was more complicated.The “nameko” library implements message handling using callbacks, which was a problem because we were trying to create request handlers that were as pure as it's possible. Callbacks are objects that exist in the process' memory during the process' lifetime, and therefore they can be modified. When you have complicated logic, a big project and a large team (and especially a distributed team) it's impossible to be absolutely certain of code modifications that are happening in run-time.
Instead, we wanted a library in which controllers and handlers are created for each request. We also wanted to route requests based on service and handler names, as opposed to objects in memory.
So what to do? We decided that we'd experiment with a new way of doing things by creating Tavrida, a proof of concept for RPC over RabbitMQ that satisfies our requirements. Once we've got things working as we think the should, we can then look at how this functionality can be integrated with existing OpenStack code.
Where can I use Tavrida?
The main aim of Tavrida is to provide intercommunication between microservices. If your application is built on traditional SOA, you'd probably prefer some a more powerful and complicated framework. Tavrida is mainly useful for services that consist of several handlers, with each server running a small number of individual services, so the microservice architecture is the ideal environment for Tavrida.Tavrida is also useful if you want to use asynchronous communications between your services. This approach is better in situations in which execution of some operations takes a long time and you don't want to block your entire application or system until the operation finishes.
In our case, we use Tavrida on an OpenStack project we're building for a large telco customer, where we have a microservices architecture and long-running operations such as virtual machine start/stop/reboots or configuration of remote network devices.
How does Tavrida work?
Tavrida can start a RabbitMQ server and route incoming messages to the corresponding service controller, with one server handling multiple services.A service is actually a class that includes request/response/error handlers, and also is able to subscribe for notifications. Each handler method is mapped to an entry point — the point that could be considered as an address -- the remote method name for request/response/error, or as a topic for publications. This entry point is the point that is exposed to other services. It consists of service name and method name.
So when the message is routed to the handler according to its entry point, Tavrisa executes custom handling logic. The first two parameters that are passed to each handler are the message and proxy objects. All following parameters are the generic RPC method parameters. For example:
from tavrida import dispatcherThe message (request/response/error/notification) object contains RabbitMQ headers that are used for routing (such as «source», «destination», «message_type», and so on), the context, which accumulates all incoming parameters in the chain of calls, and the message payload that holds the method parameters.
from tavrida import service
@dispatcher.rpc_service("test_hello")
class HelloController(service.ServiceController):
@dispatcher.rpc_method(service="test_hello", method="hello")
def handler(self, request, proxy, param):
print param
Using the proxy object it's possible to make calls to another remote service method or to publish a notification. The entry point of the handler method from which you execute the call to the remote service is considered as the source of the outgoing message, with the name of the called service and method as the destination entry point.
The same logic works for the response and error messages. On the other hand, notifications use the source entry point value as the topic (but still send it in the «source» header). Other services can use this entry point to subscribe for these notifications. For example:
@dispatcher.rpc_service("test_hello")And, of course, the request handler can send responses. Responses can be of two types: a normal response and an error that can occur at any step during request handling. If the request message has a non-empty «reply_to» header, the response/error will be delivered to this entry point hander. If «reply_to» is empty, the service handler will not send any response. By default «replty_to» is equal to «source» and the response/error is routed to to source service.
class HelloController(service.ServiceController):
@dispatcher.rpc_method(service="test_hello", method="hello")
def handler(self, request, proxy, param):
print param
proxy.publish(param="hello publication")
@dispatcher.rpc_service("test_world")
class WorldController(service.ServiceController):
@dispatcher.subscription_method(service="test_hello", method="hello")
def hello_subscription(self, notification, proxy, param):
print param # == "hello publication"
The response is returned by the handler via the instantiating response object, or just as a dict that will be converted to a response object automatically. For example:
@dispatcher.rpc_service("test_hello")Requests/responses/errors can only be sent to a remote service if the local service is aware of it. Notifications are published only if the local service is registered as publisher.
class HelloController(service.ServiceController):
@dispatcher.rpc_method(service="test_hello", method="hello")
def handler(self, request, proxy, param):
print param
proxy.test_world.world(param=12345).call()
@dispatcher.rpc_response_method(service="test_world", method="world")
def world_resp(self, response, proxy, param):
# Handles responses from test_world.world
print param # == "world response
@dispatcher.rpc_error_method(service="test_world", method="world")
def world_error(self, error, proxy):
# Handles error from test_world.world
print error.payload
@dispatcher.rpc_service("test_world")
class WorldController(service.ServiceController):
@dispatcher.rpc_method(service="test_world", method="world")
def world(self, request, proxy, param):
print param # == 12345
return {"param": "world response"}
To register the remote or local service, you call the corresponding method of the discovery object. The discovery object is an object that holds the «service_name»: «service_exchange» mappings and enables the local service to send messages to the correct exchange.
All this means that for one service to intercommunicate with one or more others, you must instantiate the discovery object, register the remote or local services and bind the discovery object to the given service before starting the server.
Let's take a look at the code example:
from tavrida import discovery
disc = discovery.LocalDiscovery()
# register remote service's exchange to send requests, responses,
errors
disc.register_remote_service("remote_service",
"remote_service_exchange")
# register service's notification exchange to publish notifications
disc.register_local_publisher("local_service",
"local_service_exchange")
# register remote notification exchange to bind to and get
notifications (subscribe)
disc.register_remote_publisher("remote_service",
"remote_notifications_exchange")
MyServiceController.set_discovery(disc)
What is under the hood?
Well, when you start the Tavrida server, the first thing it does is create all the necessary AMQP structures, such as exchanges, queues, bindings. Each service can own two exchanges: the first, which is required, is to receive requests/responses/errors, and second, which is optional, is to publish notifications. The second exchange is created only if you register the local service as a publisher.Exchanges are created according to the registrations in the discovery object. That means that you don't have to think about the manual creation of AMQP structures: Tavrida will take care of it; you just need to configure it correctly.
Each service has it's own queue. All messages that are meant for the service are delivered to this queue.
Each service queue is bound to the service's first (required) exchange with binding keys based on service name. Optionally, it may be bound to a second (optional) exchange of a remote service from which to receive notifications. In the latter case the remote (publisher) entry point will be used as the basis for the binding key.
What about performance?
Tavrida's performance is limited only by the performance of RabbitMQ. Tavrida actually has little code and therefore the additional burden is minor. Tavrida can also use sync and async engines. In fact it uses pika’s BlockingConnection() or SelectConnection() where appropriate.While preparing this article, I ran a few performance tests on my laptop, an Intel® Core™ i7-3630QM CPU @ 2.40GHz × 8 with just 8GB RAM. The load was constant during each test, and each service was instantiated only once, resulting in a single process for each service.
Here are the results:
Test 1: Publishing a message to the service A exchange and handling the message (60 seconds)
| Mode | SYNC | ASYNC |
| Time (secs) | 60 | 60 |
| Received messages | 11421 | 226603 |
Test 2: Test 1 + requests from service A to service B during handling of incoming messages (60 seconds)
| Mode | SYNC | ASYNC |
| Time (secs) | 60 | 60 |
| Requests to A | 11142 | 62466 |
| Requests from A to B | 11140 | 62355 |
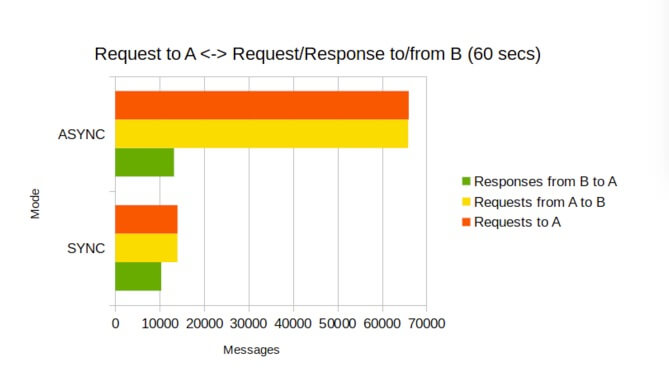
Test 3: Test 2 + service B responses to service A (60 seconds)
| Mode | SYNC | ASYNC |
| Time (secs) | 60 | 60 |
| Requests to A | 14027 | 66020 |
| Requests from A to B | 14017 | 65894 |
| Responses from B to A | 10363 | 13246 |
You'll notice that as we get more complex, the overall number of messages handled goes down. That's because in this case we have only one service, so all messages, regardless of type, are transferred to that one service’s queue. Thus requests to service A and responses from B to A are rivals. If service A gets less fewer requests it is can handle more responses, and vise versa.
Where can I get Tavrida?
If you'd like to try Tavrida for yourself, you can download it directly from my repository; you can also find the complete documentation online. At the moment, the current Tavrida client uses only synchronous mode and makes a new connection for each request, but upcoming versions will bring the persistent connections and asynchronous mode for better performance. (For my testing, the initial messages to the service A were generated by a script that publishes messages to corresponding exchange.)So what do you think? Is this useful to you? If so, we'd love for you to join us in making Tavrida better. Let us know in the comments what you'd like to see!





