
Edge Computing Challenges
Shaun O'Meara - April 16, 2020

There is a lot of talk around edge computing. What is it? What will it mean to the telco industry? Who else will benefit from it? There's also a large amount of speculation about identifying the killer application that will spark massive scale deployment of edge computing resources.
In many ways, edge computing is just a logical extension of existing software defined datacenter models. The primary goal is to provide access to compute, storage and networking resources in a standardised way, whilst abstracting the complexity of managing those resources away from applications. The key factor that is missing in many of these discussions, however, is a clear view of how we will be expected to deploy, manage and gain a clear picture of these edge resources.
The key challenge here is that those resources need to be managed in a consistent and effective way in order to ensure that application developers and owners can rely on the infrastructure, and will be able to react to changes or issues in the infrastructure in a predictable way.
The value of cloud infrastructure software such as Openstack is the provision of standardised APIs that developers can utilise to get access to resources, regardless of what they are or how they need to be managed.
With the advent of technologies such as Kubernetes, the challenge of managing the infrastructure in no way lessens; we still need to be able to understand what resources we have available, control access to them, and lifecycle manage them.
In order to enable the future goal of providing distributed ubiquitous compute resources to all who need them, where they need them, and when they need them, we have to look deeper into what is required for an effective edge compute solution.
As it appears that everyone has a slightly different perspective on what edge computing entails, in order to have a common understanding the following is the definition of edge computing used for this discussion.
In this discussion we take a broad interpretation of Edge Computing, including all compute devices that provide computing resources, that are not located in core or regional data centers, that bring computing resources closer to the end user or data collection devices.
For example, consider this hierarchy:
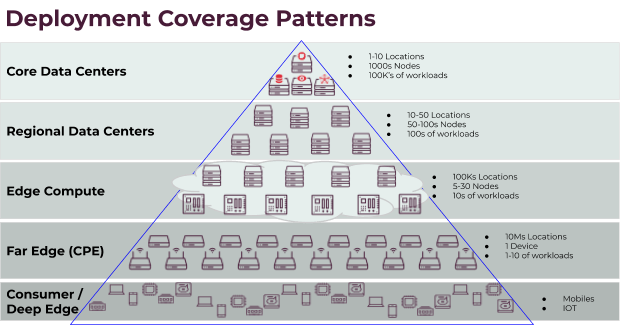 There are a number of different levels, starting with core data centers, which generally consists of fewer locations, each containing a large number of nodes and workloads. These core data centers feed into (or are fed by, depending on the direction of traffic!) the regional data centers.
There are a number of different levels, starting with core data centers, which generally consists of fewer locations, each containing a large number of nodes and workloads. These core data centers feed into (or are fed by, depending on the direction of traffic!) the regional data centers.
Regional data centers tend to be more numerous and more widely distributed than core data centers, but they are also smaller and consist of a smaller -- though still significant -- number of nodes and workloads.
From there we move down the line to edge compute locations; these locations are still clouds, consisting of a few to a few dozen nodes and hosting a few dozen workloads, and existing in potentially hundreds of thousands of locations, such as cell towers or branch offices.
These clouds serve the far edge layer, also known as "customer premise equipment". These are single servers or routers that can exist in hundreds of thousands, or even millions of locations, and serve a relatively small number of workloads. Those workloads are then accessed by individual consumer devices.
Finally the consumer or deep edge layer is where the services provided in the other layers are consumed from or from where the data is collected and processed.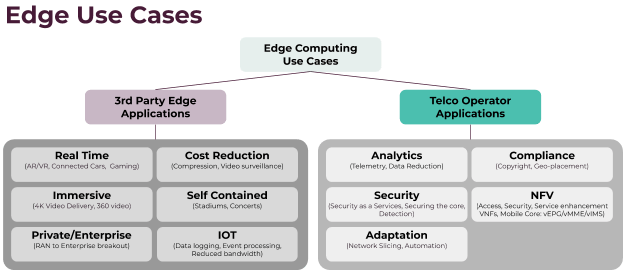 As you can see here, we can roughly divide edge use cases into third party applications and telco operator applications.
As you can see here, we can roughly divide edge use cases into third party applications and telco operator applications.
Third party applications are those that are more likely to be accessed by end users, such as providing wireless access points in a public stadium, connected cars, or on the business end, connecting the enterprise to RAN.
Operator applications, on the other hand, are more of an internal concern. They consist of applications such as geo-fencing of data, data reduction at the edge to enable more efficient analytics, or Mobile Core.
All of these applications, however, fall into the "low latency requirements" category. Other edge use cases that don't involve latency might consist of a supermarket that hosts an edge cloud that communicates with scanners customers can use to check out their groceries as they shop, or an Industrial IOT scenario in which hundreds or thousands of sensors feed information from different locations in a manufacturing plant to the plant's local edge cloud, which then aggregates the data and sends it to the regional cloud.
So taking this into account, what are the requirements for edge computing?
If this seems overwhelming, don't worry, we're here for you! Please don't hesitate to contact us and see how Mirantis can help you plan and execute your edge computing architecture.
In many ways, edge computing is just a logical extension of existing software defined datacenter models. The primary goal is to provide access to compute, storage and networking resources in a standardised way, whilst abstracting the complexity of managing those resources away from applications. The key factor that is missing in many of these discussions, however, is a clear view of how we will be expected to deploy, manage and gain a clear picture of these edge resources.
The key challenge here is that those resources need to be managed in a consistent and effective way in order to ensure that application developers and owners can rely on the infrastructure, and will be able to react to changes or issues in the infrastructure in a predictable way.
The value of cloud infrastructure software such as Openstack is the provision of standardised APIs that developers can utilise to get access to resources, regardless of what they are or how they need to be managed.
With the advent of technologies such as Kubernetes, the challenge of managing the infrastructure in no way lessens; we still need to be able to understand what resources we have available, control access to them, and lifecycle manage them.
In order to enable the future goal of providing distributed ubiquitous compute resources to all who need them, where they need them, and when they need them, we have to look deeper into what is required for an effective edge compute solution.
What is Edge Computing?
Finding a clear definition of edge computing can be challenging; there are many opinions on what constitutes the edge. Some definitions will narrow the definition of cloud, claiming that edge only includes devices that are required to support low latency workload, or that are the last computation point before the consumer, whilst others will include the consumer device or an IOT device, even if latency is not an issue.As it appears that everyone has a slightly different perspective on what edge computing entails, in order to have a common understanding the following is the definition of edge computing used for this discussion.
In this discussion we take a broad interpretation of Edge Computing, including all compute devices that provide computing resources, that are not located in core or regional data centers, that bring computing resources closer to the end user or data collection devices.
For example, consider this hierarchy:
 There are a number of different levels, starting with core data centers, which generally consists of fewer locations, each containing a large number of nodes and workloads. These core data centers feed into (or are fed by, depending on the direction of traffic!) the regional data centers.
There are a number of different levels, starting with core data centers, which generally consists of fewer locations, each containing a large number of nodes and workloads. These core data centers feed into (or are fed by, depending on the direction of traffic!) the regional data centers. Regional data centers tend to be more numerous and more widely distributed than core data centers, but they are also smaller and consist of a smaller -- though still significant -- number of nodes and workloads.
From there we move down the line to edge compute locations; these locations are still clouds, consisting of a few to a few dozen nodes and hosting a few dozen workloads, and existing in potentially hundreds of thousands of locations, such as cell towers or branch offices.
These clouds serve the far edge layer, also known as "customer premise equipment". These are single servers or routers that can exist in hundreds of thousands, or even millions of locations, and serve a relatively small number of workloads. Those workloads are then accessed by individual consumer devices.
Finally the consumer or deep edge layer is where the services provided in the other layers are consumed from or from where the data is collected and processed.
Edge Use Cases
There are a large number of potential use cases for edge computing, with more being identified all the time. For example: As you can see here, we can roughly divide edge use cases into third party applications and telco operator applications.
As you can see here, we can roughly divide edge use cases into third party applications and telco operator applications.Third party applications are those that are more likely to be accessed by end users, such as providing wireless access points in a public stadium, connected cars, or on the business end, connecting the enterprise to RAN.
Operator applications, on the other hand, are more of an internal concern. They consist of applications such as geo-fencing of data, data reduction at the edge to enable more efficient analytics, or Mobile Core.
All of these applications, however, fall into the "low latency requirements" category. Other edge use cases that don't involve latency might consist of a supermarket that hosts an edge cloud that communicates with scanners customers can use to check out their groceries as they shop, or an Industrial IOT scenario in which hundreds or thousands of sensors feed information from different locations in a manufacturing plant to the plant's local edge cloud, which then aggregates the data and sends it to the regional cloud.
Edge Essential Requirements
The delivery of any compute service has a number of requirements that need to be met. With edge computing, the same delivery of a massively distributed compute service takes all those requirements and compounds them, not only because of the scale, but also because access (both physically and via the network) may be restricted due to device/cloud location.So taking this into account, what are the requirements for edge computing?
| Area | Detail |
| Security (isolation) |
|
| Resource management |
|
| Telemetry Data |
|
| Operations |
|
| Open Standards |
|
| Stability and Predictability |
|
| Performance |
|
| Abstraction |
|
Sound familiar?
If you're thinking that this sounds a lot like the theory behind cloud computing, you're right. In many ways, "edge" is simply cloud computing taken a bit further out of the datacenter. The distinction certainly imposes new requirements, but the good news is that your cloud skills can be brought to bear to get you started.If this seems overwhelming, don't worry, we're here for you! Please don't hesitate to contact us and see how Mirantis can help you plan and execute your edge computing architecture.





