
OpenStack Benchmarking for Humans
OpenStack is, without any doubt, a huge ecosystem of many coordinated services. Rally is a benchmarking tool that hepls to answer following question: “How does OpenStack behave at different scales?”. To make this possible, Rally automates and unifies OpenStack deployments, cloud verification and benchmarking.
Rally does it in a generic way, making it possible to check whether OpenStack is going to perform well on, let’s say, a 1k servers installation under high load. Thus it can be used as a monitoring tool for an OpenStack CI/CD system that would continuously measure its SLA, performance and stability.
Rally was originally designed for machine testing. This means that communication with rally is only possible by CLI which communicates directly with database. But what if you want run just some simple basic test? You must define your scenarios with correct contexts. Next you must have some rally environment, but you must have access and policy for connecting to this VM. Yes this is not all, but you must source your environment and call start task with knowing where your right task lives.
Setting up Benchmark Server
You need to install MySQL database and provide identity backends.
pip install rally
After the application code is installed
rally deployment create --file=openstack.json --name=openstack
+--------------------------------------+----------------------------+------------+------------------+--------+
| uuid | created_at | name | status | active |
+--------------------------------------+----------------------------+------------+------------------+--------+
| d43fsfse-grgg-546j-grt3-fdsf4f3gh6dd | 2015-02-28 10:11:12.324323 | openstack | deploy->finished | |
+--------------------------------------+----------------------------+------------+------------------+--------+
Using deployment : <Deployment UUID>
Please note the last line in the output. It says that new deployment will be used by Rally. That means that all the benchmarking operations from now on are going to be performed on this deployment.
Finally,the deployment check command lets you verify health status of current deployment.
rally deployment check
keystone endpoints are valid and following services are available:
+----------+----------------+-----------+
| services | type | status |
+----------+----------------+-----------+
| cinder | volume | Available |
| glance | image | Available |
| heat | orchestration | Available |
| heat-cfn | cloudformation | Available |
| keystone | identity | Available |
| nova | compute | Available |
+----------+----------------+-----------+
After Rally is installed we can start using it. As already mentioned, Rally is designed more for machines and less for humans. There is no simple way how we can start task directly from Python. For example if you want start any simple scenario you must import all pieces which are required by that particular task. This means that you have about five imports for any simple scenario!
Using the Benchmark Server
Rally has standard openstack command-line interface built on oslo.config which is by the way best cli tool for Python. Rally’s CLI provides basic management commands:
- info - Print information about available scenarios
- task - Manage benchmarking tasks and results.
- show - View resourses, provided by OpenStack cloud represented by deployment.
- verify - Compare and verify two results.
- deployment - Manage OpenStack environments
rally --debug task start --task create-and-delete-wordpress.yaml
--------------------------------------------------------------------------------
Task 1b06712e-c30c-436c-9eea-8c05332ee18d: finished
--------------------------------------------------------------------------------
test scenario HeatStacks.create_and_delete_stack
args position 0
args values:
{
"runner": {
"type": "constant",
"concurrency": 1,
"times": 100
},
"args": {
"template_path": "templates/wordpress_ha.yaml.template"
},
"context": {
"users": {
"project_domain": "default",
"users_per_tenant": 3,
"tenants": 2,
"resource_management_workers": 30,
"user_domain": "default"
}
}
}
+-------------------------------------------------------------------------------------------+
| Response Times (sec) |
+-------------------+--------+--------+--------+--------+--------+--------+---------+-------+
| action | min | median | 90%ile | 95%ile | max | avg | success | count |
+-------------------+--------+--------+--------+--------+--------+--------+---------+-------+
| heat.create_stack | 10.555 | 12.951 | 15.691 | 16.554 | 19.904 | 13.224 | 100.0% | 100 |
| heat.delete_stack | 7.943 | 9.239 | 10.533 | 11.417 | 14.284 | 9.498 | 100.0% | 100 |
| total | 18.606 | 22.305 | 25.794 | 27.113 | 30.464 | 22.722 | 100.0% | 100 |
+-------------------+--------+--------+--------+--------+--------+--------+---------+-------+
Load duration: 2272.51969004
Full duration: 2283.31879997
HINTS:
* To plot HTML graphics with this data, run:
rally task report 1b06712e-c30c-436c-9eea-8c05332ee18d --out output.html
* To generate a JUnit report, run:
rally task report 1b06712e-c30c-436c-9eea-8c05332ee18d --junit --out output.xml
* To get raw JSON output of task results, run:
rally task results 1b06712e-c30c-436c-9eea-8c05332ee18d
Test Scenarios
One of the important features is server side serving of Rally test scenarios.We have used this pattern in our Heat Extension where we manage all available templates and their environments directly on server. This simple enhancement allows end users to easily start complex Infrastructure benchmark tests without any deep knowledge requirements. In this case we automatically load all services and their scenarios from setup path.
Set rally root at ...
RALLY_ROOT = '/srv/rally/scenarios'
Sample directory structure of the test scenarion folders and full stucture would be:
/srv/rally/scenarios/tasks/scenarios/nova/boot-and-delete.yml
/srv/rally/scenarios/tasks/scenarios/keystone/create.yml
/srv/rally/scenarios/tasks/scenarios/whatever/awesome.yml
Plugin System
Rally is pluggable platform which has all stuff registered and if trying to start task directly from Python you must import every piece of shit, but you don’t, because is there simple way how you can specify what you need. See two examples. Both loads same stuff because we load recursively all members.
Plugin configuration example:
RALLY_PLUGINS = [
'rally.plugins.openstack',
'rally.plugins.common'
]
RALLY_PLUGINS = [
'rally.plugins',
]
Long Running Task
In Django is one correct way how you can manage long running tasks and it is use Celery which is awesome and powerfull framework. But for installing without requirements is there simple implementation which creates Thread for every task, which is basically wrong and may cause overload your Horizon. For overwrite async task behaviour set your new awesome behaviour to benchmark_dashboard.utils.async.run_async
Simple implementation of long runing task
def run_async(method):
# call Celery or whatever
Thread(target=method, args=[]).start()
OpenStack Benchmark Dashboard
Setup easy for some end-users, but what you want just test some scenarios without any deep knowledge of Rally internals? For every simple test you must spend a lot of time if you haven’t CI machinery. We spent some time looking for existing solutions and finally Michael has created a simple Benchmark Dashboard for Horizon. Benchmark dashboard communicates with directly the CLI commands and also with database where Rally stores it’s results.
Features
- start task for concrete environment
- list, search and download task result
- delete task result
- edit scenario and context before start task (not fully implemented)
Screenshots
Finally some dashboard screenshots from our development environment. The views use database stored outputs from Rally test runs.
Modal form where you can select test scenarios with proper context
List of running and finished tasks with actions
This list of tasks is fully filterable
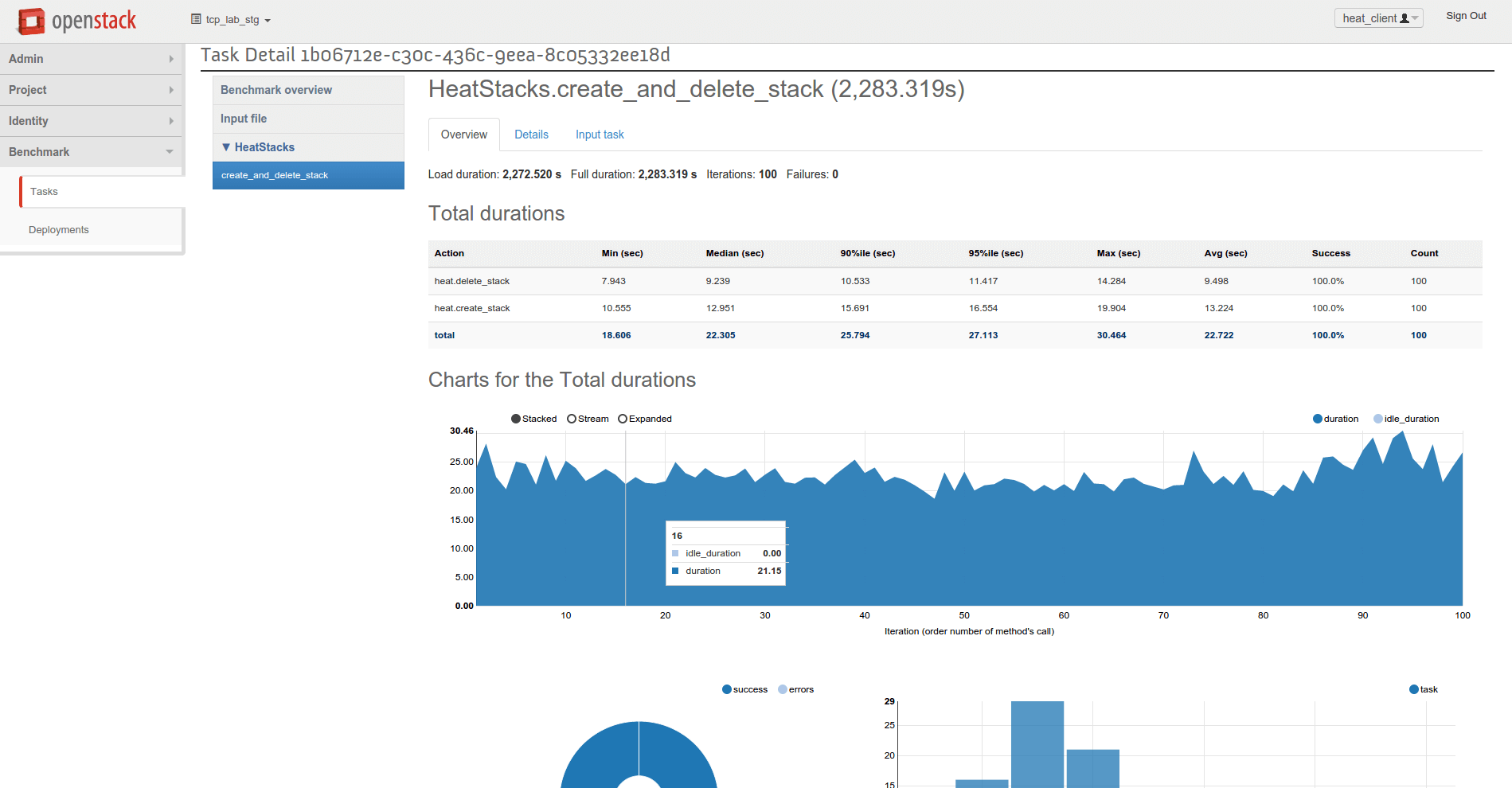
Task detail shows us results in graphic form
Cooperation
The rally board is in it’s beta stage, the source code on GitHub’s tcpcloud/horizon-rally-dashboard repository, you are welcome to contribute.
Conclusion
Rally is very interesting benchmarking framework, that is suitable for benchmarking various transformation metrics of OpenStack resources. It covers all possible screnarios for tests and uses statistical methods to determine the success rate of the test results. Our dashboard allows regular users to benchmark OpenStack resources and even advanced scenarios with rally framework and observe results in horizon dashboard along other OpenStack panels.
Michael Kuty, Ales Komarek






