
Upgrading OpenStack workloads: introducing Pumphouse
Now that the tenth release of OpenStack has hit the market, it’s natural to see a multitude of deployments based on different releases out there. Here at Mirantis we sometimes face a situation where customers have their own flavor of OpenStack up and running, but want to replace it with Mirantis OpenStack to get the advantages of the latest OpenStack features. At the same time, however, most customers already have workloads in their cloud, and they want to move them to Mirantis OpenStack as is, or with minimal changes so their processes don't break.
That’s the inspiration for Pumphouse – an open source project that works with the Fuel API to enable us to onboard customer workloads to Mirantis OpenStack with minimal additional hardware needed. The eventual goal for Pumphouse is to replace a customer’s ‘Frankenstack’ with Mirantis OpenStack on the same set of physical servers.
In this series of posts, we're going to look at why we need Pumphouse, what it does, and how it does it.
What does Pumphouse do?
Pumphouse deals with two clouds: Source and Destination. Its task is to move resources from one cloud to another cloud. Once Source nodes have been cleared, Pumphouse can also automatically reassign them from the Source to the Destination cloud if the Destination cloud doesn't have enough capacity to accept more workloads.
In Pumphouse, a workload is a set of virtual infrastructure resources provided by OpenStack to run a single application or a number of integrated applications working together.
The simplest definition of a workload is a single virtual server with all resources that were used to create it. We consider that a minimal possible workload. However, usually the migration of a single server doesn’t make sense, so the Pumphouse UI doesn't support migration of individual virtual servers. (It is still possible with the Pumphouse CLI script, however.)
OpenStack groups virtual servers in Nova into projects. Pumphouse can then migrate a project as a whole, with all servers and other types of resources that belong to the project, such as flavors, images and networks.
Pumphouse also replicates credentials used to authenticate and authorize users in projects. Credentials include OpenStack tenants, users, roles, and role assignments.
How does Pumphouse move workloads?
Once we understood what we wanted to move, we had to decide how we wanted to move it.
Users will probably want their migrated resources to appear just as they had in the original cloud. That means Pumphouse must preserve as much of the meta-data of each resource as possible. It can copy parameters between the Source cloud's database and the Destination cloud's database. but that would be difficult if the database schema changes, especially when moving to a new release of OpenStack.
Another option is to use the OpenStack APIs as much as possible. APIs are much more stable (in theory, at least) then database models, so we decided that Pumphouse would avoid talking to the Source and Destination cloud databases, and instead leverage API calls to copy meta-data.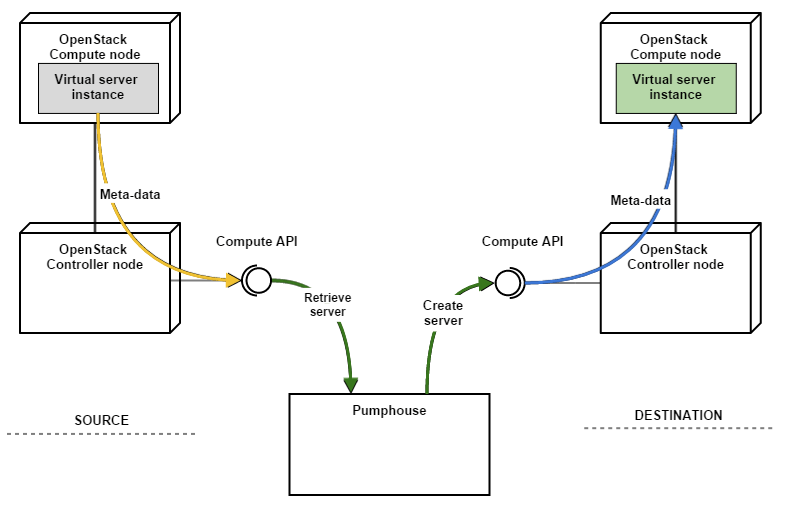
But what about actual data users generate and store in the Source cloud? Pumphouse has to move that, too. User data usually resides in server ephemeral storage and/or in virtual block volumes.
Fortunately, the OpenStack APIs provide ways to transfer that data without using lower-level technologies (such as SSH/dd/etc). For ephemeral storage, there is the Nova ‘snapshot’ feature, which creates a Glance image with the contents of the disk of the virtual server. For virtual block volumes, OpenStack allows us to copy data from the Cinder volume to a Glance image, and then restore the volume in Cinder from the Glance image in the Destination cloud. In both cases, the resulting image can be moved as usual.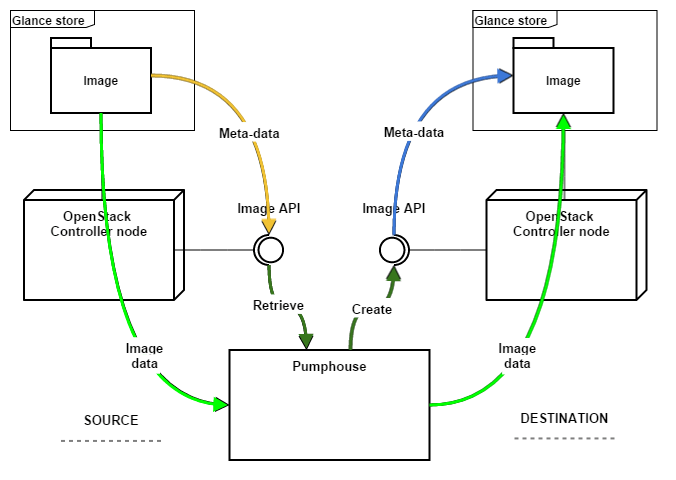
Of course, for some tasks we have to use direct SQL queries to the database. This is especially true for user passwords. Obviously, you can neither query nor set them via the OpenStack API, even as encrypted hashes. Pumphouse requires access to Keystone’s tables in the Source and Destination databases to reset passwords.
What's behind Pumphouse?
So before we move on to seeing Pumphouse in action, it's helpful to understand the structure behind it. Pumphouse is a Python application that provides an HTTP-based API. It relies on the Taskflow library for determined and parallelized execution of atomic tasks. There are tasks to fetch meta-data for different resources from the Source cloud, tasks to upload meta-data to the Destination cloud, and tasks that perform specific operations on resources in clouds, such as suspending the server or creating a snapshot.
Pumphouse normally requires administrative access to both the Source and the Destination OpenStack APIs, and read/write access to the Identity tables in the OpenStack database. Access credentials must be provided via configuration file.
To upgrade hypervisor hosts, Pumphouse requires access to the IPMI network that connects them, and indeed all hosts. IPMI access credentials are also required. They must be provided in the configuration file (inventory.yaml).
Pumphouse must be installed on a system that has network connectivity to all OpenStack API endpoints so it can access both admin and public versions of those APIs. The Pumphouse host also must be able to access the IPMI interfaces of host nodes.
Pumphouse also has CLI scripts that allow you to perform migration tasks in stand-alone mode without running Pumphouse service. This includes pumphouse and pumphouse-bm for operations with hypervisor hosts (evacuation and upgrade).
Pumphouse is being developed in an open Github repository under the Apache 2.0 license. Come, see, fork and hack with us!
What’s next?
In this intro article I defined a problem that we are going to solve in the Pumphouse application. In short, Pumphouse is intended to do the following:
move workloads defined in a standard way from one cloud to another, assuming both clouds support the OpenStack APIs, and using those APIs wherever possible;
reassign hypervisor hosts from one cloud to another, assuming the destination cloud is a Mirantis OpenStack cloud, using the Fuel API for provisioning and deployment;
preserve the meta-data of resources being moved as much as possible.





