
Mirantis OpenStack 7.0 Enhances Resilience at Scale
- September 30, 2015
Hardening a large-scale, complex production environment is not a trivial task. It includes selecting specific software packages, performing bug fixes and making sure they are stable, and validating interoperability with other packages and third-party options. This work is bundled into a set of all dependent packages for the solution, either to be obtained automatically or included in the distribution itself, and fully documented with known integration attributes and reference architectures. In addition, the software security is audited and patched, working to eliminate possible vulnerabilities in the code.
And after hardening the solution, efforts are made to ensure the solution is resilient and capable of handling environmental failures while continuing to provide services. In a large distributed environment this becomes even more important. Each major component needs resiliency at-scale to be built-in.
The aggregation of these efforts encompasses hardening, and strengthens the solution's reliability.
In a previous blog, we described how Mirantis development stays as close to the community trunk as possible. I’ll take it a step further here and describe the flow of development and releases of the community version and Mirantis distributions. Figure 1 shows the typical software development timeline. In this case, it’s the OpenStack community development timeline. The line with blue points represents the main trunk of development code. Each blue point represents time progression with code improvements, bug fixes, and new features added to the code pool. Eventually, a point in time is selected for a code freeze defining the scope of included features, and a branch (yellow) is formed with the intent of making it an official release. That release candidate undergoes automated general function testing and bug fixing in the effort to create a stable release. Community testing is performed on a non-HA single-node, focused only on fundamental OpenStack functionality. Peripheral 3rd-party driver and plugin testing is left to the individual vendor as their responsibility. There is a possibility of losing some fidelity in overall integration with this process.
Then, after its release, bugs continue to be reported and fixes are eventually (when the volunteer community finds the cycles to get to it) included into a patch release, represented by the yellow points.
[caption id="attachment_651667" align="alignleft" width="710"]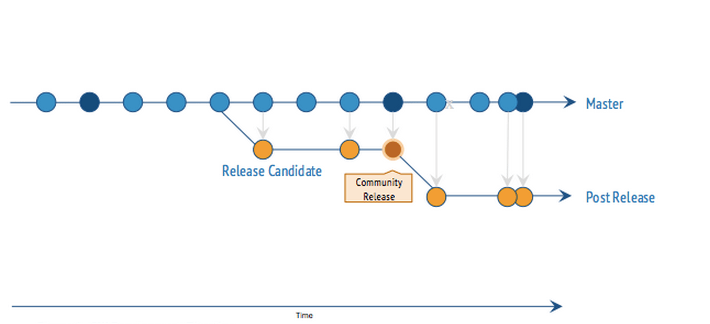 Figure 1 - Software Development Timeline[/caption]
Figure 1 - Software Development Timeline[/caption]
It’s of considerable interest that well over a thousand python and deb packages exist in a distribution of OpenStack with roughly3.2 million lines of code across all the modules. On top of that, each of these modules has its own versioning history. Selecting the correct aggregation and version of these packages to create a stable and resilient single solution is Mirantis’ specialty.
In Figure 2, the red points represent the Mirantis OpenStack distribution timeline. We start with a community release, then put it through extensive tests (in addition to what the community has already performed) at scale in a dedicated physical lab built of hundreds of nodes and tens of thousands of instances to uncover issues that only truly materialize when running under real load in large production environments.
The additional tests performed by Mirantis include:
After the major release, enhancements and bug fixes continue and are bundled into Mirantis patches and hotfixes (as necessary). All of the individual fixes are submitted through community processes, and most eventually get included in the main community code base. The few fixes that do not get merged into the community code are typically due to other committers providing a different fix for the same bug. Unfortunately, due to timing in the upstream OpenStack community, there can often be a lengthy time lag between when the fix is submitted and its eventual inclusion in the community release. Mirantis patches are hosted on public repositories for immediate availability.
[caption id="attachment_651675" align="alignleft" width="742"]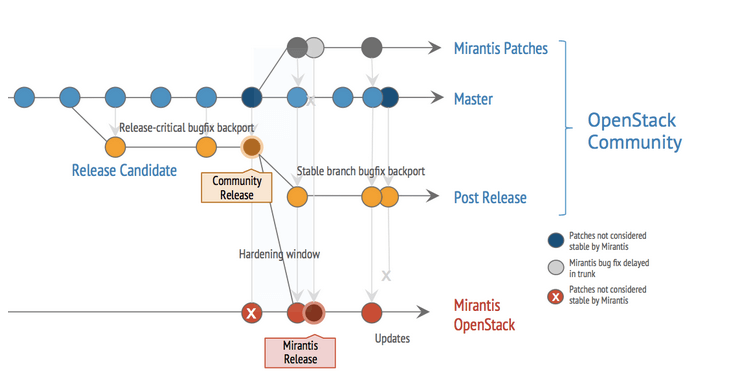 Figure 2 - Mirantis OpenStack Development Timeline[/caption]
Figure 2 - Mirantis OpenStack Development Timeline[/caption]
Mirantis continues the process of streamlining the deployment of complex OpenStack environments with hardened packages that create a more resilient, more highly available, and more reliable solution.
And after hardening the solution, efforts are made to ensure the solution is resilient and capable of handling environmental failures while continuing to provide services. In a large distributed environment this becomes even more important. Each major component needs resiliency at-scale to be built-in.
The aggregation of these efforts encompasses hardening, and strengthens the solution's reliability.
Hardening
Hardening gives assurance that all components will work together without failure at scale in high availability configurations.Four Main Aspects of Hardening for Mirantis OpenStack 7.0
At Mirantis, we follow four principles of hardening:- Validation Testing & Security Auditing - Automated process protocols for repeatable and reliable results to shorten acceptance time
- Bundling
- Reference Architectures
- Third Party Integrations - partner plugin collaborations for example:
- Cisco Application-Centric Infrastructure (ACI) SDN
- SolidFire Storage
- Calico SDN
Mirantis OpenStack Hardening Activities
Harding involves several steps:- Upstream first - all fixes are developed upstream
- Extensive testing on the distribution as a whole (including middleware, third party components etc.)
- Real-world customer feedback
- Expertise on what to test
- Finding & fixing dependencies of a given bug-fix in addition to the bug itself
- Multiple types of concurrent tests
- Open-sourcing test-frameworks e.g. Rally, Shaker
Step-by-Step Guide to Hardening
The amount of work required to properly curate the entirety of OpenStack, as exemplified above, can’t be expected of a single person. Mirantis has hundreds of development engineers working to do exactly that. Let’s compare the community OpenStack process with that of Mirantis OpenStack.In a previous blog, we described how Mirantis development stays as close to the community trunk as possible. I’ll take it a step further here and describe the flow of development and releases of the community version and Mirantis distributions. Figure 1 shows the typical software development timeline. In this case, it’s the OpenStack community development timeline. The line with blue points represents the main trunk of development code. Each blue point represents time progression with code improvements, bug fixes, and new features added to the code pool. Eventually, a point in time is selected for a code freeze defining the scope of included features, and a branch (yellow) is formed with the intent of making it an official release. That release candidate undergoes automated general function testing and bug fixing in the effort to create a stable release. Community testing is performed on a non-HA single-node, focused only on fundamental OpenStack functionality. Peripheral 3rd-party driver and plugin testing is left to the individual vendor as their responsibility. There is a possibility of losing some fidelity in overall integration with this process.
Then, after its release, bugs continue to be reported and fixes are eventually (when the volunteer community finds the cycles to get to it) included into a patch release, represented by the yellow points.
[caption id="attachment_651667" align="alignleft" width="710"]
Figure 1 - Software Development Timeline[/caption]It’s of considerable interest that well over a thousand python and deb packages exist in a distribution of OpenStack with roughly3.2 million lines of code across all the modules. On top of that, each of these modules has its own versioning history. Selecting the correct aggregation and version of these packages to create a stable and resilient single solution is Mirantis’ specialty.
In Figure 2, the red points represent the Mirantis OpenStack distribution timeline. We start with a community release, then put it through extensive tests (in addition to what the community has already performed) at scale in a dedicated physical lab built of hundreds of nodes and tens of thousands of instances to uncover issues that only truly materialize when running under real load in large production environments.
The additional tests performed by Mirantis include:
- Control- and data-plane - OpenStack Rally is used used to benchmark and ensure API performance of the control-plane under load, and Mirantis Shaker is used to confirm data-plane performance. Mirantis both contributes these tests into the community and uses tests contributed by other community members. This strengthens the base of testing for all.
- Negative - Injection of invalid data to a system under load. For example, providing invalid set of parameters in an API request.
- Destructive (Resiliency and HA) - Node, Controller, and Service failure injection is simulated to validate proper functioning of HA architecture
- Longevity - Long-term testing of OpenStack under load to find intermittent hard-to-find issues.
- Open-source middleware - For example, Pacemaker, Corosync, RabbitMQ, MongoDB, and Galera are tested as a whole to generate proven reference architectures
- 3rd-party drivers - Additional plugins and drivers are integrated into the testing to ensure extensibility and flexibility of solution options
After the major release, enhancements and bug fixes continue and are bundled into Mirantis patches and hotfixes (as necessary). All of the individual fixes are submitted through community processes, and most eventually get included in the main community code base. The few fixes that do not get merged into the community code are typically due to other committers providing a different fix for the same bug. Unfortunately, due to timing in the upstream OpenStack community, there can often be a lengthy time lag between when the fix is submitted and its eventual inclusion in the community release. Mirantis patches are hosted on public repositories for immediate availability.
[caption id="attachment_651675" align="alignleft" width="742"]
Figure 2 - Mirantis OpenStack Development Timeline[/caption]Resilience
In addition to hardening the distribution as a whole, a complex solution such as OpenStack needs to be resilient at all levels when operating at scale. It needs to have high-availability from both the control plane and data plane perspective. This includes the controllers, the services running on those controllers, the networks, the storage controllers, and the data stored on the storage controllers. That’s a lot of things to think about. Mirantis is constantly putting effort to enhancing OpenStack’s reliability. More on this topic in a subsequent blog.Intensified Longevity Testing
The nature of complexity produces scenarios where not all possible situations can be perfectly predicted and planned for, at least without some element of trial and error. Mirantis has expanded the breadth and depth of testing these possibilities by enhancing our longevity testing. By taking an environment and running multiple tests against it for long periods of time, rather than just testing against a freshly deployed environment, we are able to uncover bugs that would not otherwise be found. For example, in LP#1490500, a heavy load for a period of time was found to possibly fill the mysql-binlog, and that had a subsequent effect of blocking Horizon from functioning properly.More Reliable Upgradability
Mirantis OpenStack has previously automated a way for customers to receive patch notifications and apply fixes so that the cloud is kept up-to-date and reliable. With our notification system and early access program, you’re able to get some of those fixes in advance and test them against non-production environments so you can better predict user and system behavior. In Mirantis OpenStack 7.0, we’ve enhanced the upgrade rollback capability for changes applied to components in case something goes wrong. We’ve added partition preservation so that the node redeployment process prevents the deleting of data on its partitions. This eliminates the need to manually backup and restore the data to perform rollbacks. With partition preservation, any data kept in dedicated partitions, and not in the root partition, can be preserved. This applies for example, to Ceph data, Swift data, Nova instance cache, and customized databases. This saves time and better ensures the integrity of the data during these sensitive operations.Middleware Improvements
Mirantis applies hardening and resiliency testing to 3rd-party and non-OpenStack open-source middleware as well. As an example, Mirantis discovered through scale testing that when RabbitMQ, as a shared queuing resource, gets loaded with a large spike of instructions in the queue, it tends to have higher latency responses. This can cause unwanted behavior from Pacemaker and Corosync, which believe there is something wrong with the specific RabbitMQ service. The latency detection can cause Pacemaker and Corosync to try to “fix” the overall system by “shooting” the afflicted RabbitMQ service, removing the problematic rabbit from service.Hunting rabbits in this way actually makes the symptom worse by redirecting the load to remaining servers. Rather than shooting these rabbits, we have made changes to how the queues are handled, getting through these increased latency periods.Mirantis continues the process of streamlining the deployment of complex OpenStack environments with hardened packages that create a more resilient, more highly available, and more reliable solution.




