
Multi-cloud application orchestration on Mirantis Cloud Platform using Spinnaker
- May 21, 2017

If there's one thing that's become obvious in the last year or so it's that when it comes to cloud, business success is more than just "installing OpenStack" or "deploying Kubernetes"; it's about doing whatever it takes to run applications in the most appropriate environment, and in the most reliable way. At the Boston OpenStack Summit in May, I demonstrated a hybrid cloud application that ran Big Data analysis using a combination of components running on bare metal, in virtual machines, and in containers. In this blog, I'll explain how that worked.
Customers are the same. They don't care if they have the very best OpenStack distribution if they can't get their users to stop dropping their credit cards onto AWS or GCE because the experience is so much better.
To that end, we recently shipped Mirantis Cloud Platform, which is no longer “just” an OpenStack or Kubernetes distribution with an installer. Instead it includes DriveTrain, which covers an ecosystem of salt formulas (~140), unified metadata models called reclass, Jenkins with CI/CD pipelines, Gerrit for review and other support services.
While DriveTrain is intended to deploy OpenStack and Kubernetes and keep them up-to-date with the latest versions and improvements, it's not solely for the underlying IaaS. Instead, it can also enable application orchestration higher in the stack -- in other words, the workloads you run on that IaaS.
By providing an experience more like AWS or GCE, we're enabling customers to focus on solving their problems. Therefore MCP is a generic platform, which allows us to focus on use cases such as Big Data, IoT or NFV clouds. In Boston, we showed the application orchestration of a sample Big Data use case. Let’s go through details.
Taking the OpenStack arena as an example, after 7 years of existence, deployments are finally growing, and OpenStack is mature enough to run enterprise production workloads. Legacy applications need a transition period from VMs to containers, and that will take some time. Therefore enterprise needs to have a unified hybrid platform, where you can split workloads between containers, VMs and non-virtualized resources. You can take best-of-breed from all three workloads and tune them for best performance and optimal costs. For example, MCP 1.0 comes with OpenStack, Kubernetes and OpenContrail, making it possible to create an environment where all those components work together to create a platform for legacy application stacks that are in various stages of transformation.
Let’s go through the steps and architecture of this unified platform. First we needed to provision all hardware nodes in our datacenter with a basic operation system, and OpenStack provides that capability via the Ironic project, Bare Metal-as-a-Service (BMaaS). These servers then form the foundation nodes for the control plane or support services, as well as compute power for any workloads, as in Figure 1.
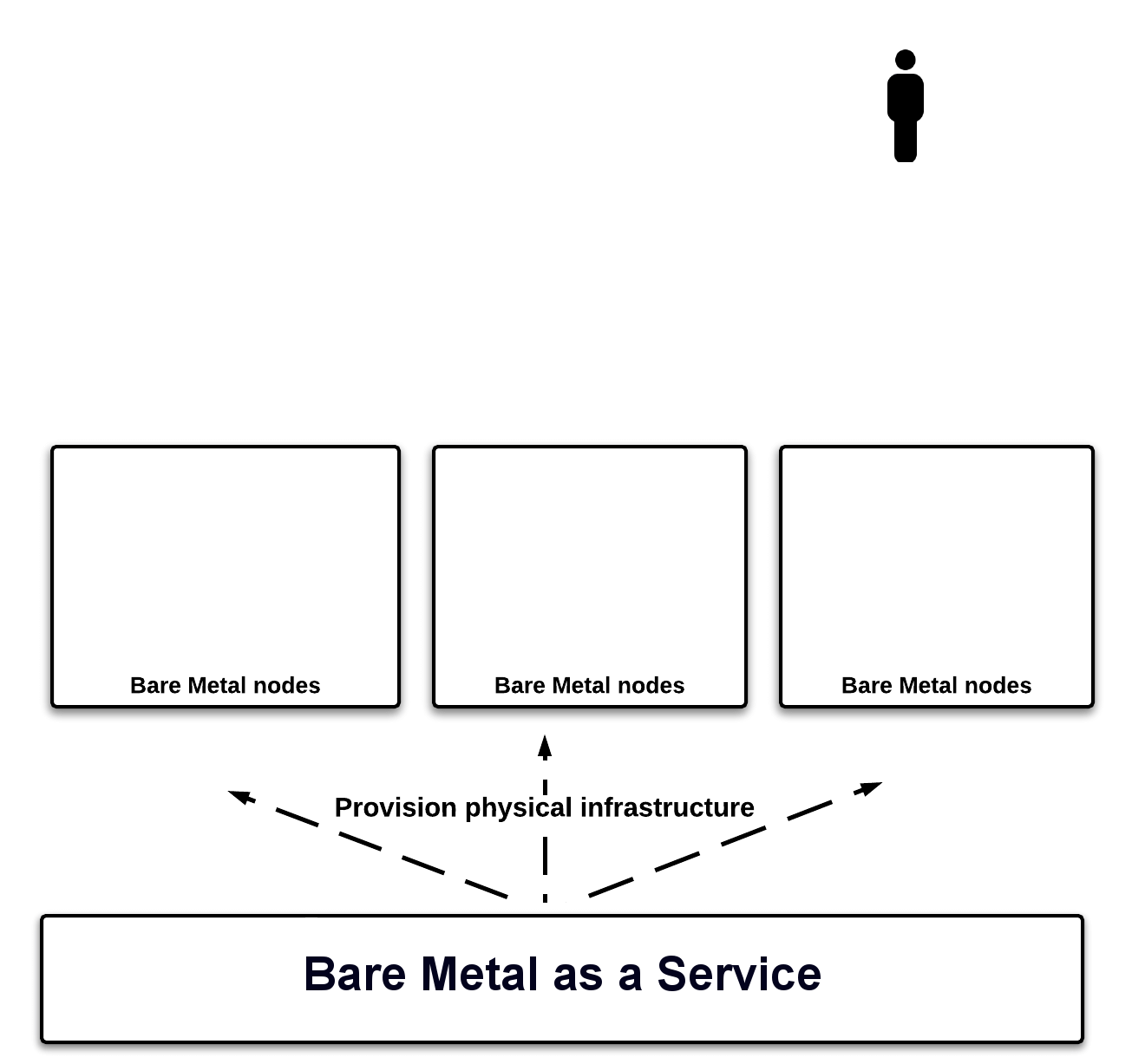
Figure 1: Our hardware nodes were split into three groups.
For this example, we split our servers into three groups and we deployed Kubernetes cluster on baremetal on one group, standard OpenStack compute nodes on the second group, and left the third group alone to act as non-virtualized servers.
OpenContrail SDN enabled us to create a single network layer and connect VMs, containers and baremetal nodes. OpenContrail has a Neutron plugin for OpenStack, and also a CNI plugin for Kubernetes, which enables us to use same network technology stack for both. Bare metal servers are then connected through Top-of-Rack (ToR) switches via VXLAN and the OVS-DB protocol, as in Figure 2.
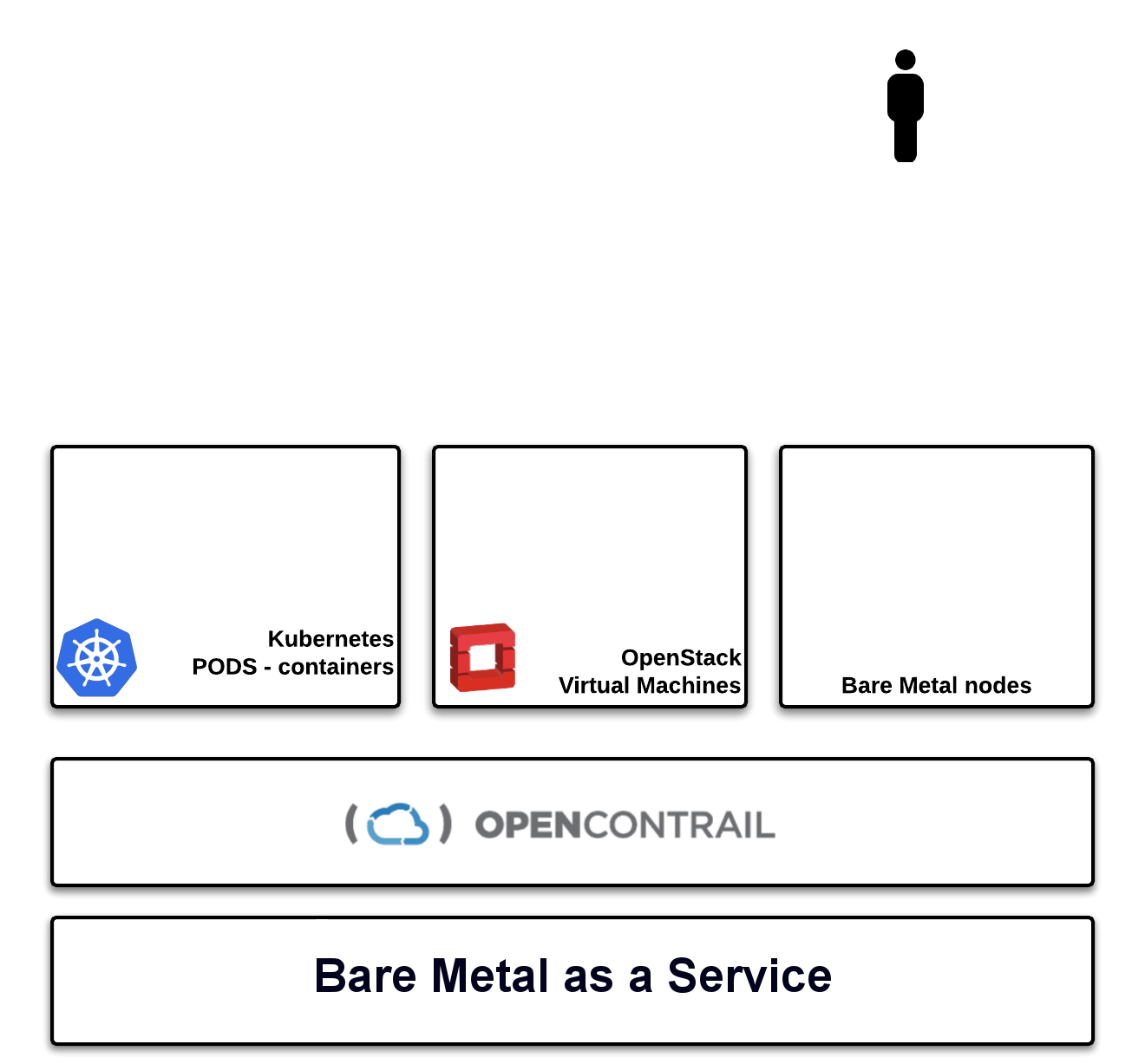 Figure 2: One group of servers is dedicated to Kubernetes, one to OpenStack, and one to bare metal nodes; they're tied together with OpenContrail networking.
Figure 2: One group of servers is dedicated to Kubernetes, one to OpenStack, and one to bare metal nodes; they're tied together with OpenContrail networking.
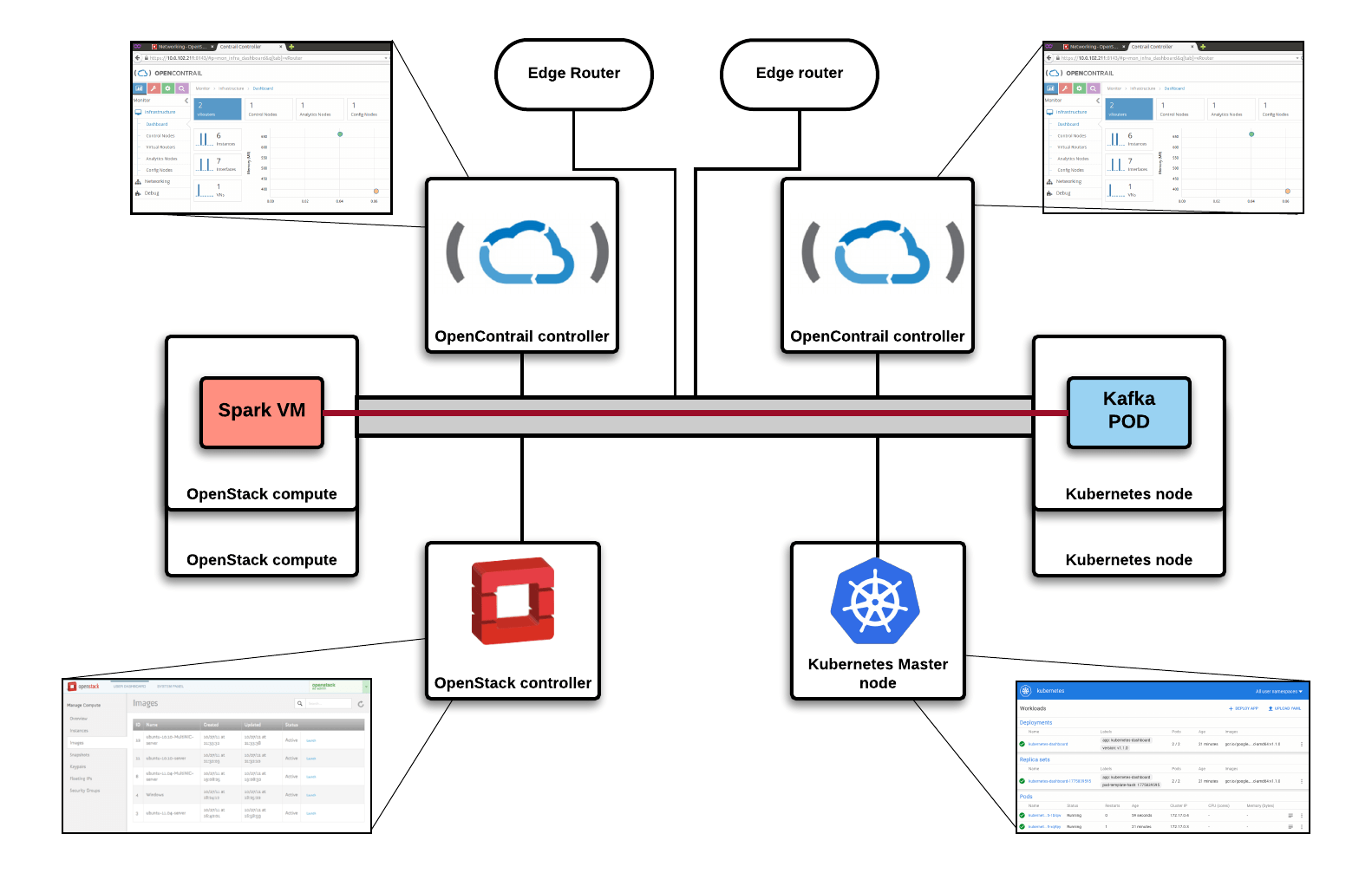
In Figure 3, you can see the demo stack, where we have OpenStack and Kubernetes running with two independent OpenContrail control planes, which are federated via BGP (available since version 2.2x). This feature enables you to build independent OpenStack regions and federate their network stack across multiple sites while still maintaining separate failure domains. Any virtual networks can be directly routable by setting a route target, which establishes a direct datapath from container to VM. Traffic does not go through any gateway or network node, because vRouter creates an end-to-end MPLSoUDP or VXLAN tunnel. As you can see, we've created a direct path between the kafka pod (container) and the Spark VM.
Now that we know what we're trying to deploy, let's look at how we actually deployed it.
The real value and usability of this platform comes with higher orchestration. Fortunately, we can provide multi-cloud orchestration using a tool called Spinnaker. Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. It was developed primarily by Netflix for AWS, but it's gotten a lot of traction and provides drivers for AWS, OpenStack, Kubernetes, Google Cloud platform and Microsoft Azure.
Spinnaker's main goal is to bake and rollout immutable images on different providers with different strategies, where you can manage load balancers, security groups and server groups made up of VMs and containers. (One important note here is that Spinnaker is not a PaaS, as some people think. It is really for large app orchestration.) Figure 4 shows that we have enabled two providers: OpenStack and Kubernetes.

Figure 4: Spinnaker has two providers enabled: Kubernetes and OpenStack.
Spinnaker has a simple UI, which enables us to build complex pipelines that include stages such as "manual judgement", "run script", "webhook" or "jenkins job". MCP includes Jenkins as part of DriveTrain, so integration with Spinnaker pipelines is very easy. I can imagine using Spinnaker just for multiple stage Jenkins pipelines for upgrades of hundreds of different OpenStack sites.
Figure 5 shows our the Big Data infrastructure we want Spinnaker to orchestrate on top of MCP. Basically, we deploy HDFS on couple of bare metal servers, Spark in VMs, and kafka with zookeeper in containers. (We'll talk more about the actual stack in the next subsection.)
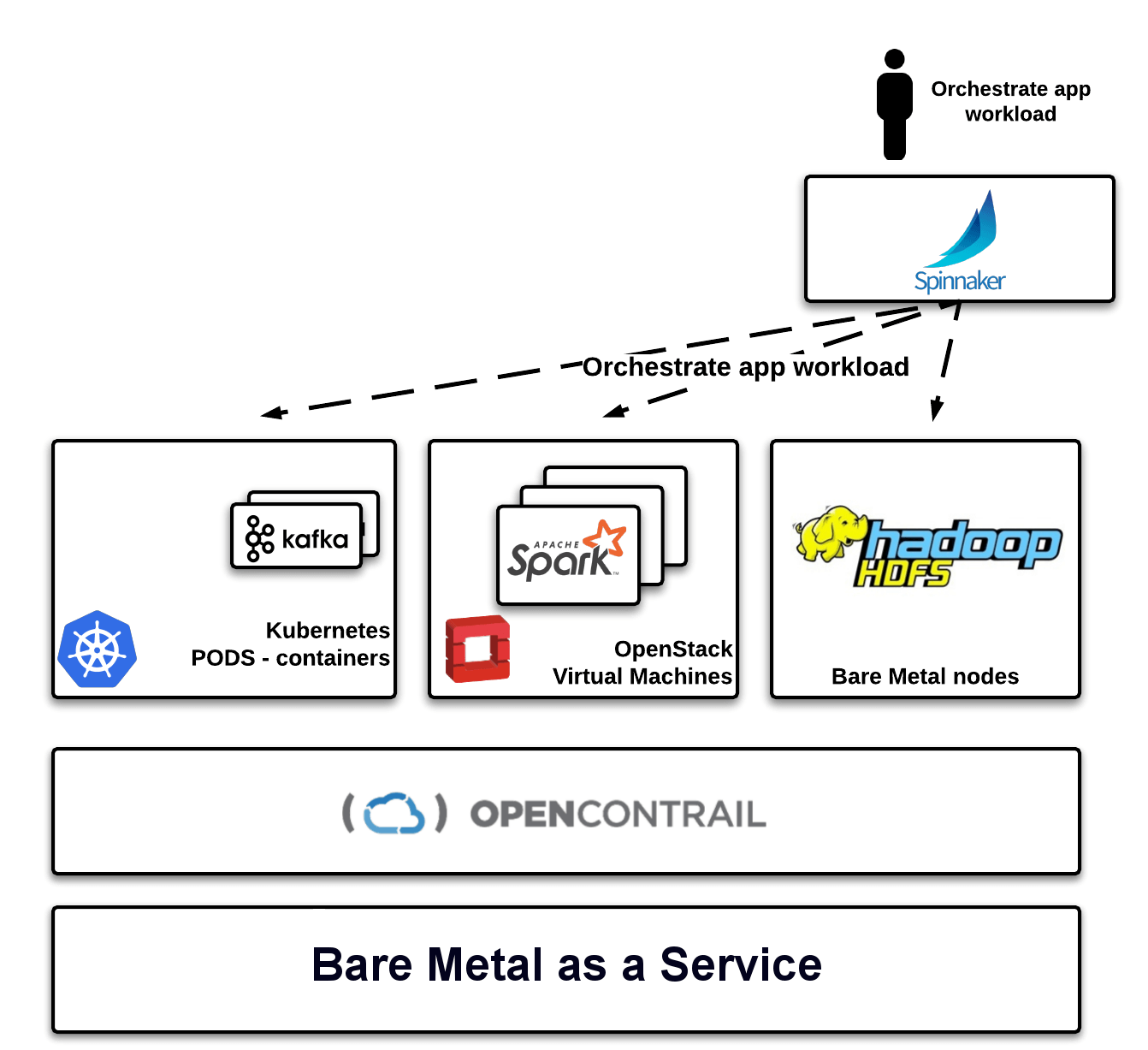
Figure 5: Spinnaker will orchestrate Kafka on our Kubernetes cluster, Apache Spark on our VMs, and Hadoop HDFS on the bare metal nodes.
Figure 6 shows our big data infrastructure pipeline, which we'll need later for our Big Data use case. As you can see, you can create multiple stages with different dependencies, and each stage can do notifications on slack, email, and so on.
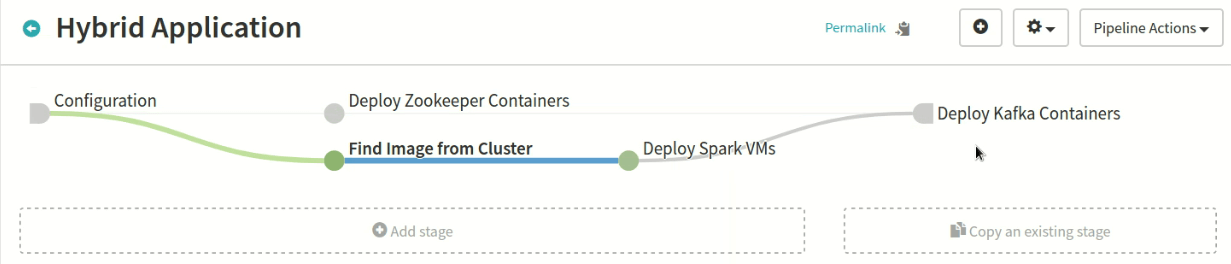
Figure 6: The infrastructure pipeline shows multiple stages with different dependencies.
Finally, Figure 7 shows the view of deployed server groups, with Spark on VMs and kafka/zookeeper on kubernetes containers.
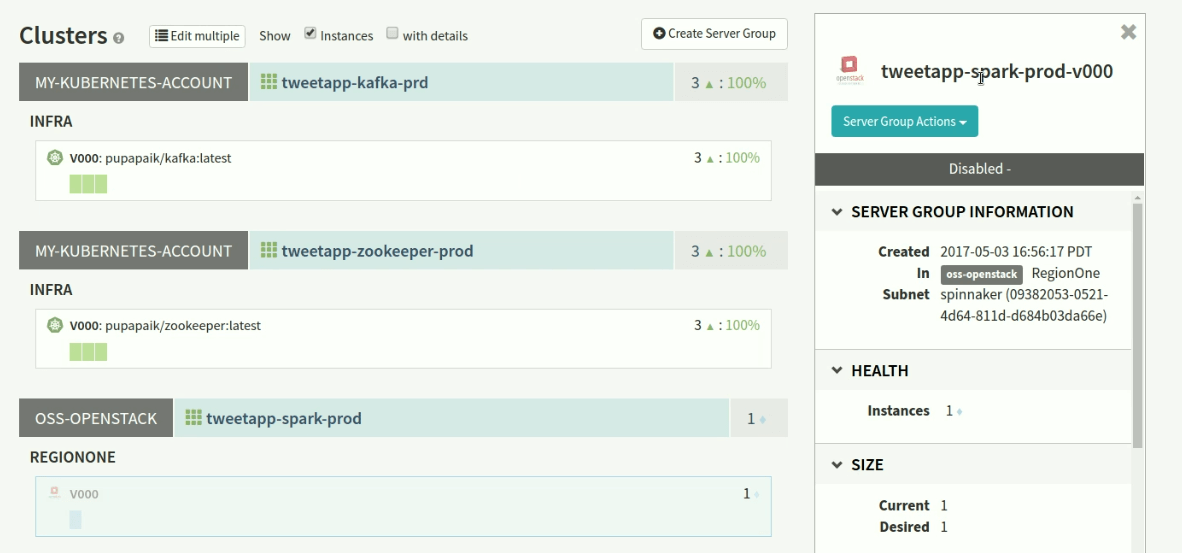
Figure 7: Spinnaker's view of the deployed server groups; Spark is running on VMs, and Kafka and Zookeeper are running in Kubernetes-orchestrated containers.
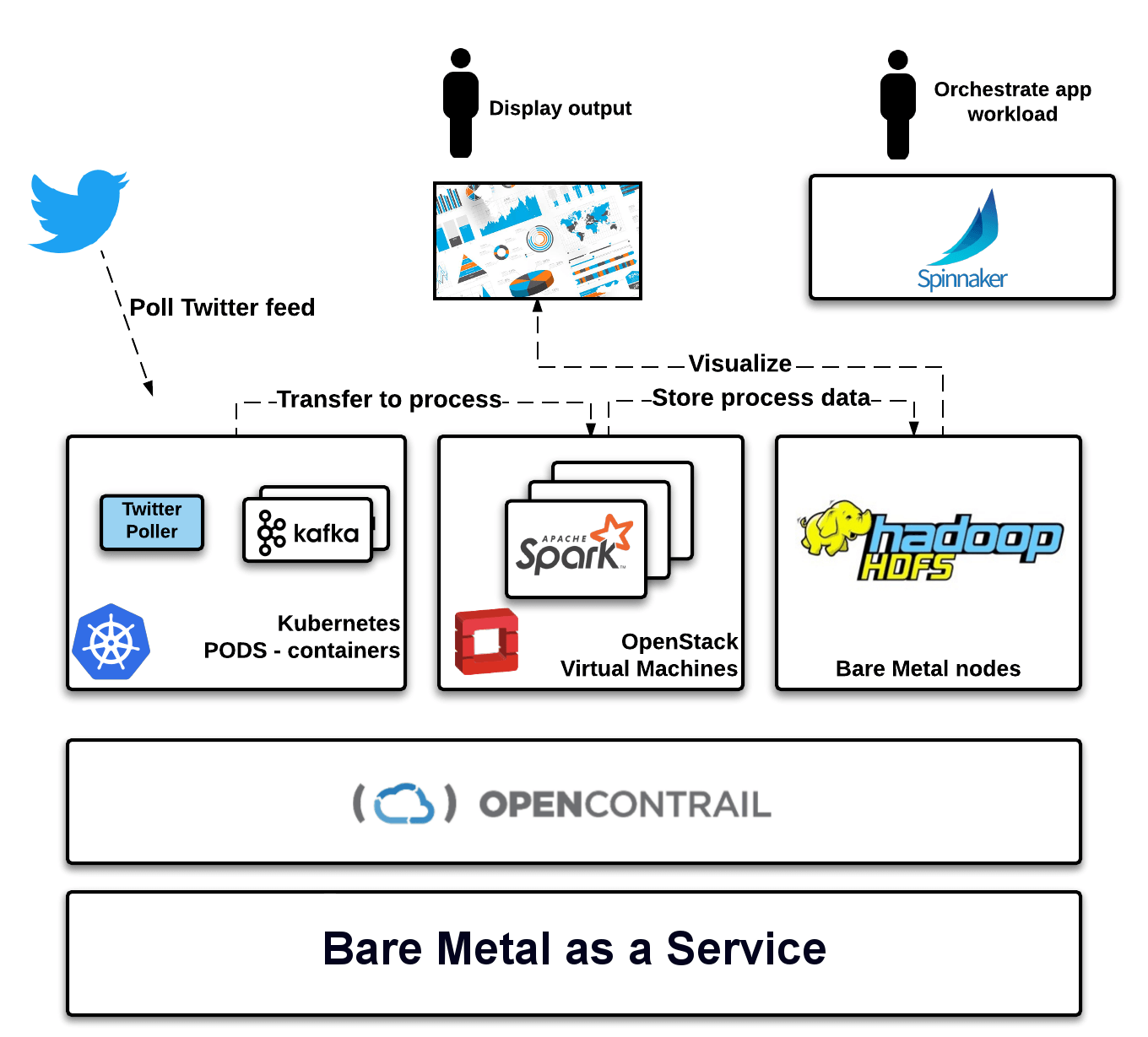
Figure 8: The Twitter Poller pulls data into Kafka, which then sends it to Spark for analysis before it gets sent to Hadoop for visualization and storage.
Our stack consists of following components:

Figure 9: The app displays the data in realtime, showing the relative popularity of various terms by adjusting their size in the tag cloud. For example, the two most popular topics were IoT and Big Data.
As you can see, once you have a flexible platform such as MCP, it's much easier to tackle various use cases and help customers to onboard their workloads and satisfy their requirements through an open source platform. We've shown a relatively simple view of this setup; you can see a more in-depth look by viewing the Deep Demo session on orchestration I gave at the summit.
Next time, I'll try to bring insight more into the NFV and Video streaming use cases.
Users aren't looking for technology
Have you ever brought your car to a mechanic and asked for a new oxygen sensor? Of course not. You go in asking for a solution to bad gas mileage or because your check engine light is on. You don't care how they fix it, you just want it fixed.Customers are the same. They don't care if they have the very best OpenStack distribution if they can't get their users to stop dropping their credit cards onto AWS or GCE because the experience is so much better.
To that end, we recently shipped Mirantis Cloud Platform, which is no longer “just” an OpenStack or Kubernetes distribution with an installer. Instead it includes DriveTrain, which covers an ecosystem of salt formulas (~140), unified metadata models called reclass, Jenkins with CI/CD pipelines, Gerrit for review and other support services.
While DriveTrain is intended to deploy OpenStack and Kubernetes and keep them up-to-date with the latest versions and improvements, it's not solely for the underlying IaaS. Instead, it can also enable application orchestration higher in the stack -- in other words, the workloads you run on that IaaS.
By providing an experience more like AWS or GCE, we're enabling customers to focus on solving their problems. Therefore MCP is a generic platform, which allows us to focus on use cases such as Big Data, IoT or NFV clouds. In Boston, we showed the application orchestration of a sample Big Data use case. Let’s go through details.
MCP as a unified platform for VMs, containers and baremetal
Over the last year containers and Kubernetes have gotten a lot of traction in the community. Everyone talks about containers for workloads, but enterprise applications are not ready to just jump in containers.Taking the OpenStack arena as an example, after 7 years of existence, deployments are finally growing, and OpenStack is mature enough to run enterprise production workloads. Legacy applications need a transition period from VMs to containers, and that will take some time. Therefore enterprise needs to have a unified hybrid platform, where you can split workloads between containers, VMs and non-virtualized resources. You can take best-of-breed from all three workloads and tune them for best performance and optimal costs. For example, MCP 1.0 comes with OpenStack, Kubernetes and OpenContrail, making it possible to create an environment where all those components work together to create a platform for legacy application stacks that are in various stages of transformation.
Let’s go through the steps and architecture of this unified platform. First we needed to provision all hardware nodes in our datacenter with a basic operation system, and OpenStack provides that capability via the Ironic project, Bare Metal-as-a-Service (BMaaS). These servers then form the foundation nodes for the control plane or support services, as well as compute power for any workloads, as in Figure 1.

Figure 1: Our hardware nodes were split into three groups.
For this example, we split our servers into three groups and we deployed Kubernetes cluster on baremetal on one group, standard OpenStack compute nodes on the second group, and left the third group alone to act as non-virtualized servers.
OpenContrail SDN enabled us to create a single network layer and connect VMs, containers and baremetal nodes. OpenContrail has a Neutron plugin for OpenStack, and also a CNI plugin for Kubernetes, which enables us to use same network technology stack for both. Bare metal servers are then connected through Top-of-Rack (ToR) switches via VXLAN and the OVS-DB protocol, as in Figure 2.
 Figure 2: One group of servers is dedicated to Kubernetes, one to OpenStack, and one to bare metal nodes; they're tied together with OpenContrail networking.
Figure 2: One group of servers is dedicated to Kubernetes, one to OpenStack, and one to bare metal nodes; they're tied together with OpenContrail networking.In Figure 3, you can see the demo stack, where we have OpenStack and Kubernetes running with two independent OpenContrail control planes, which are federated via BGP (available since version 2.2x). This feature enables you to build independent OpenStack regions and federate their network stack across multiple sites while still maintaining separate failure domains. Any virtual networks can be directly routable by setting a route target, which establishes a direct datapath from container to VM. Traffic does not go through any gateway or network node, because vRouter creates an end-to-end MPLSoUDP or VXLAN tunnel. As you can see, we've created a direct path between the kafka pod (container) and the Spark VM.

Now that we know what we're trying to deploy, let's look at how we actually deployed it.
Multi-Cloud orchestration with Spinnaker
Now we have a platform that can can run any kind of workload, but for developers or operators, what's more important is to how to orchestrate applications. Users do not want to go into OpenStack and manually start a VM, then go to kubernetes to start a container, and after that plug a non-virtualized bare metal node into the network through a ToR switch. That process is complex, error-prone, and time-consuming.The real value and usability of this platform comes with higher orchestration. Fortunately, we can provide multi-cloud orchestration using a tool called Spinnaker. Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. It was developed primarily by Netflix for AWS, but it's gotten a lot of traction and provides drivers for AWS, OpenStack, Kubernetes, Google Cloud platform and Microsoft Azure.
Spinnaker's main goal is to bake and rollout immutable images on different providers with different strategies, where you can manage load balancers, security groups and server groups made up of VMs and containers. (One important note here is that Spinnaker is not a PaaS, as some people think. It is really for large app orchestration.) Figure 4 shows that we have enabled two providers: OpenStack and Kubernetes.

Figure 4: Spinnaker has two providers enabled: Kubernetes and OpenStack.
Spinnaker has a simple UI, which enables us to build complex pipelines that include stages such as "manual judgement", "run script", "webhook" or "jenkins job". MCP includes Jenkins as part of DriveTrain, so integration with Spinnaker pipelines is very easy. I can imagine using Spinnaker just for multiple stage Jenkins pipelines for upgrades of hundreds of different OpenStack sites.
Figure 5 shows our the Big Data infrastructure we want Spinnaker to orchestrate on top of MCP. Basically, we deploy HDFS on couple of bare metal servers, Spark in VMs, and kafka with zookeeper in containers. (We'll talk more about the actual stack in the next subsection.)

Figure 5: Spinnaker will orchestrate Kafka on our Kubernetes cluster, Apache Spark on our VMs, and Hadoop HDFS on the bare metal nodes.
Figure 6 shows our big data infrastructure pipeline, which we'll need later for our Big Data use case. As you can see, you can create multiple stages with different dependencies, and each stage can do notifications on slack, email, and so on.

Figure 6: The infrastructure pipeline shows multiple stages with different dependencies.
Finally, Figure 7 shows the view of deployed server groups, with Spark on VMs and kafka/zookeeper on kubernetes containers.

Figure 7: Spinnaker's view of the deployed server groups; Spark is running on VMs, and Kafka and Zookeeper are running in Kubernetes-orchestrated containers.
Big Data Twitter analytics
We wanted to use a real example use case and not just show orchestration or ping between VMs and containers, so we picked Big Data because we are working on similar implementations at a couple of customers. To make it manageable for a short demo, we created a simple app, with real time Twitter streaming API processing, as you can see in Figure 8.
Figure 8: The Twitter Poller pulls data into Kafka, which then sends it to Spark for analysis before it gets sent to Hadoop for visualization and storage.
Our stack consists of following components:
- Tweetpub - Reads tweets from the Twitter Streaming API and puts them into a Kafka topic
- Apache Kafka - Messaging that transmits data from Twitter into Apache Spark. Alongside Kafka, we run Apache Zookeeper as a requirement.
- Apache Spark - Data processing, running TweeTics job.
- TweeTics - Spark job that parses tweets from Kafka and stores hashtags popularity as text files to HDFS.
- Apache Hadoop HDFS - Data store for processed data.
- Tweetviz - Reads processed data from HDFS and shows hashtag popularity as a tag cloud.
- openstack
- kubernetes
- k8s
- python
- golang
- sdn
- nfv
- weareopenstack
- opencontrail
- docker
- hybridcloud
- aws
- azure
- openstacksummit
- mirantis
- coreos
- redhat
- devops
- container
- api
- bigdata
- cloudcomputing
- iot

Figure 9: The app displays the data in realtime, showing the relative popularity of various terms by adjusting their size in the tag cloud. For example, the two most popular topics were IoT and Big Data.
As you can see, once you have a flexible platform such as MCP, it's much easier to tackle various use cases and help customers to onboard their workloads and satisfy their requirements through an open source platform. We've shown a relatively simple view of this setup; you can see a more in-depth look by viewing the Deep Demo session on orchestration I gave at the summit.
Next time, I'll try to bring insight more into the NFV and Video streaming use cases.





