
Object Storage approaches for OpenStack Cloud: Understanding Swift and Ceph
Overview
Many people confuse object storage with block-level storage such as iSCSI or FibreChannel (SAN), but there is a great deal of difference between them. While SAN exposes only block devices to the system (the /dev/sdb linux device name is a good example), object storage can be accessed only with a specialized client app (e.g., the box.com client app).
Block storage is an important part of cloud infrastructure. Its main use cases are storing images for virtual machines or storing a user’s files (e.g., backups of all sorts, documents, pictures). The main advantage of object storage is very low implementation cost compared to enterprise-grade storage, while ensuring scalability and data redundancy. There seem to be a couple of widely recognizable implementations of object storage. Here we'll compare two of them that can be interfaced with OpenStack.
OpenStack Swift
Swift architecture
OpenStack Object Storage (Swift) provides redundant, scalable distributed object storage using clusters of standardized servers. "Distributed" means that each piece of the data is replicated across a cluster of storage nodes. The number of replicas is configurable, but should be set to at least three for production infrastructures.
Objects in Swift are accessed via the REST interface, and can be stored, retrieved, and updated on demand. The object store can be easily scaled across a large number of servers.
Each object's access path consists of exactly three elements:
/account/container/object
The object is the exact data input by the user. Accounts and containers provide a way of grouping objects. Nesting of accounts and containers is not supported.
Swift software is divided into components, which include account servers, container servers, and object servers that handle storage, replication, and management of objects, containers, and accounts. Apart from that, yet another machine called a proxy server exposes the swift API to users and streams objects to and from the client upon request.
Account servers provide container listings for a given account. Container servers provide object listings in given containers. Object servers simply return or store the object itself, given its full path.
Rings
Since user data is distributed over a set of machines, it is essential to keep track of where they reside. Swift does this by maintaining internal data structures called "rings." The rings are replicated on all the Swift cluster nodes (both storage and proxy). This way Swift avoids a flaw of many distributed filesystems that rely on a centralized metadata server, as typically, that metadata store that becomes a chokepoint for calls to reference metadata. No update to the ring is necessary to store or remove an individual object, as rings represent cluster membership better than a central data map. This benefits IO operations, greatly reducing access latency.
There are separate rings for account databases, container databases, and individual objects, but each ring works in the same way. In short—for a given account, container, or object name, the ring returns information on its physical location within storage nodes. Technically, this action is carried out using the consistent hashing method. Some good explanations on how the rings work can be found on our blog and here.
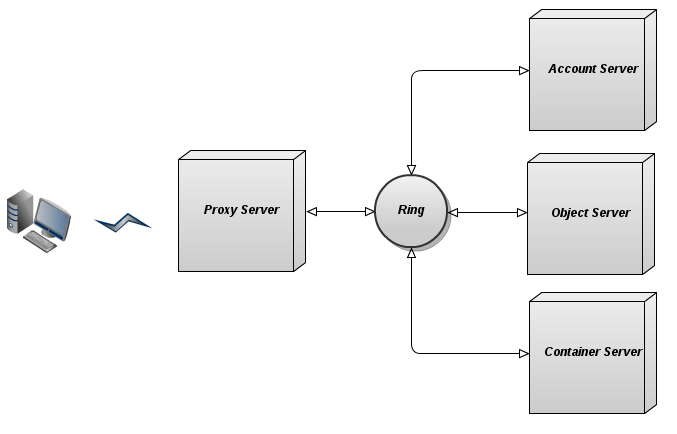
Proxy Server
The proxy server exposes public API and serves requests to storage entities. For each request, the proxy server looks up the location of the account, container, and object using the ring. Once it has their location, it routes the request accordingly. Objects are streamed between the proxy server and client directly and no buffering is enabled (to make it even more clear: even though it has "proxy" in the name, the "proxy" server does not do any "proxying" to speak of, such as you might be familiar with from http).
Object server
This is a simple BLOB storage server that can store, retrieve, and delete objects. Objects are stored as binary files on the storage nodes with metadata stored in the file’s extended attributes (xattrs). This requires that the underlying filesystem choice for object servers support xattrs on files.
Each object is stored using a path derived from the object name’s hash and the operation’s time stamp. The last write always wins (including in distributed scenarios, creating a need for globally synchronized clocks) and ensures that the latest object version will be served. A deletion is also treated as a version of the file (a 0 byte file ending with ”.ts”, which stands for tombstone). This ensures that deleted files are replicated correctly and older versions don’t magically reappear due to failure scenarios.
Container server
The container server handles listings of objects. It doesn’t know where those objects are, just what objects are in a specific container. The listings are stored as sqlite3 database files, and replicated across the cluster in a way similar to objects. Statistics are also tracked that include the total number of objects, and total storage usage for that container.
A special process—swift-container-updater—continuously sweeps the container databases on the node it works on, and updates the account database if a container's data changes. It uses the ring to locate the account to update.
Account server
This is similar to the container server, but handles container listings.
Features and functions
- Replication: The number of object copies that can be configured manually.
- Object upload is a synchronous process: The proxy server returns a “201 Created” HTTP code only if more than half the replicas are written.
- Integration with OpenStack identity service (Keystone): Accounts are mapped to tenants.
- Auditing objects consistency: the md5 sum of an object on the file system compared to its metadata stored in xattrs.
- Container synchronization: This makes it possible to synchronize containers across multiple data centers.
- Handoff mechanism: It makes it possible to use an additional node to keep a replica in case of failure.
- If the object is more than 5 Gb, it has to be split: These parts are stored as separate objects and could be read simultaneously.
Ceph
Ceph is a distributed network storage with distributed metadata management and POSIX semantics. The Ceph object store can be accessed with a number of clients, including a dedicated cmdline tool, FUSE, and Amazon S3 clients (through a compatibility layer, called "S3 Gateway"). Ceph is highly modular - different sets of features are provided by different components which one can mix and match. Specifically, for object store accessible via s3 API it is enough to run three of them: object server, monitori server, RADOS gateway.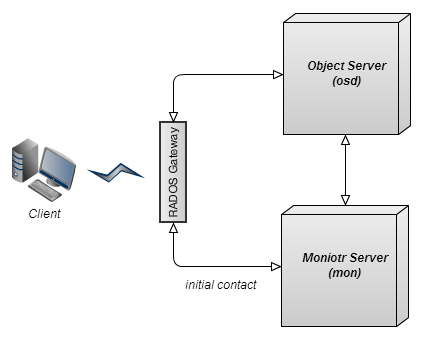
Monitor server
ceph-mon is a lightweight daemon that provides a consensus for distributed decision-making in a Ceph cluster. It also is the initial point of contact for new clients, and will hand out information about the topology of the cluster. Normally there would be three ceph-mon daemons, on three separate physical machines, isolated from each other; for example, in different racks or rows.
Object server
The actual data put onto Ceph is stored on top of a cluster storage engine called RADOS, deployed on a set of storage nodes.
ceph-osd is the storage daemon that runs on every storage node (object server) in the Ceph cluster. ceph-osd contacts ceph-mon for cluster membership. Its main goal is to service object read/write/etc. requests from clients, It also peers with other ceph-osds for data replication. The data model is fairly simple at this level. There are multiple named pools, and within each pool there are named objects, in a flat namespace (no directories). Each object has both data and metadata. The data for an object is a single, potentially big, series of bytes. The metadata is an unordered set of key-value pairs. Ceph filesystem uses metadata to store file owner, etc. Underneath, ceph-osd stores the data on a local filesystem. We recommend Btrfs, but any POSIX filesystem that has extended attributes should work.
CRUSH algorithm
While Swift uses rings (md5 hash range mapping against sets of storage nodes) for consistent data distribution and lookup, Ceph uses an algorithm called CRUSH for this. In short, CRUSH is an algorithm that can calculate the physical location of data in Ceph, given the object name, cluster map and CRUSH rules as input. CRUSH describes the storage cluster in a hierarchy that reflects its physical organization, and thus can also ensure proper data replication on top of physical hardware. Also CRUSH allows data placement to be controlled by policy, which allows CRUSH to adapt to changes in the cluster membership.
Rados Gateway
radosgw is a FastCGI service that provides a RESTful HTTP API to store objects and metadata on the Ceph cluster.
Features and functions
- Partial or complete reads and writes
- Snapshots
- Atomic transactions with features like append, truncate, and clone range
- Object level key-value mappings
- Object replicas management
- Aggregation of objects (series of objects) into a group, and mapping the group to a series of OSDs
- Authentication with shared secret keys: Both the client and the monitor cluster have a copy of the client’s secret key
- Compatibility with S3/Swift API
Feature summary
| Swift | Ceph | |
| Replication | Yes | Yes |
| Max. obj. size | 5gb (bigger objects segmented) | Unlimited |
| Multi DC installation | Yes (replication on the container level only, but a blueprint proposed for full inter dc replication) | No (demands asynchronous eventual consistency replication, which Ceph does not yet support) |
| Integration /w Opentsack | Yes | Partial (lack of Keystone support) |
| Replicas management | No | Yes |
| Writing algorithm | Synchronous | Synchronous |
| Amazon S3 compatible API | Yes | Yes |
| Data placement method | Ring (static mapping structure) | CRUSH (algorithm) |
Sources
Official Swift documentation – Source for description of data structure.
Swift Ring source code on Github – Code base of Ring and RingBuilder Swift classes.
Blog of Chmouel Boudjnah – Contains useful Swift hints.
Official Ceph documentation - Base source for description of data structure.





