
The Architecture of a Kubernetes Cluster

One of the biggest challenges for implementing cloud native technologies is learning the fundamentals—especially when you need to fit your learning into a busy schedule.
In this series, we’ll break down core cloud native concepts, challenges, and best practices into short, manageable exercises and explainers, so you can learn five minutes at a time. These lessons assume a basic familiarity with the Linux command line and a Unix-like operating system—beyond that, you don’t need any special preparation to get started.
Last time, we set up a local Kubernetes environment and learned three different ways to interact with a cluster: the kubectl command line tool, the Kubernetes Web Dashboard, and the Lens IDE. In this lesson, we’ll explore the architecture of a Kubernetes cluster: its core components, how they interact with one another, and how we interact with them.
Table of Contents
The Architecture of a Kubernetes Cluster ←You are here
How to Use Kubernetes Secrets with Environment Variables and Volume Mounts
How to Use StatefulSets and Create a Scalable MySQL Server on Kubernetes
Universal node components
A Kubernetes cluster is made up of nodes. A node is simply a compute resource: it can be either a virtual or physical computer. Last time, we noted that our Minikube cluster is a single-node cluster, meaning that it consists of only one machine–typically a containerized or virtual machine running on our laptop or desktop.
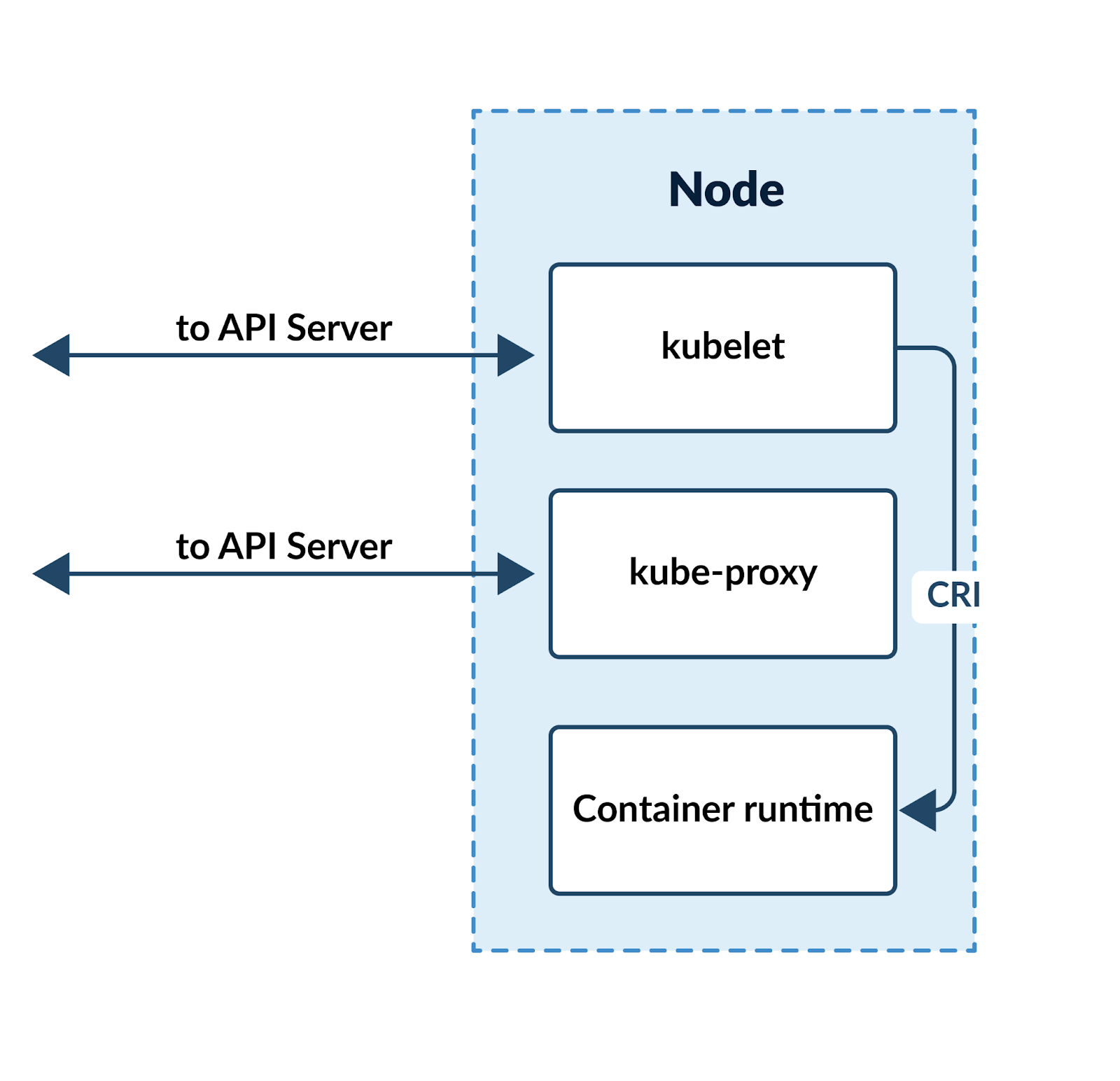
Any node might need to step up and run workloads at any time, so the components required to make that happen are found on every node. Those components include:
A container runtime: This is the component that actually runs containers on a node. Today, Kubernetes supports a variety of runtimes, including containerd, CRI-O, Mirantis Container Runtime, and others.
kubelet: A kubelet runs on every node and mediates between the control plane and the node in question, passing instructions to the container runtime—”Start this workload!”—and then monitoring the status of the job. In order to facilitate the use of different runtimes, the kubelet communicates with the container runtime through a standardized Container Runtime Interface (or CRI).
kube-proxy: Containerized workloads will need to be able to communicate with one another and the world outside the cluster. In other words, we’re going to have a lot of complicated networking going on! The kube-proxy component is a given node’s on-site network expert, managing network rules and connections on the node.
We can visualize the fundamental components of a node like this:
The Kubernetes control plane
Nodes in Kubernetes clusters are assigned roles. Start your Minikube cluster and then run the following command:
% kubectl get nodesYou should see one node, named minikube, because this is a single-node cluster.
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 99s v1.23.1Note the roles listed here. The minikube node is fulfilling the roles of control-plane and master. What does this mean?
The control plane coordinates the assignment of workloads—meaning containerized applications and services—to other nodes. If there are no other nodes in the cluster, as in our case, then the control plane node has to roll up its sleeves and get its hands dirty.
In a real-world, production-grade Kubernetes deployment, you will almost certainly have many nodes dedicated to running workloads—these are sometimes called worker nodes. Additionally, you will likely have multiple nodes in the control plane. (We’ll discuss this and other architectural patterns shortly.)
In such a scenario, the control plane is dedicated to ensuring that the current state of the cluster matches a pre-defined specification (or spec)—the desired state of the cluster. If our specification says that an instance of NGINX should be running, and the control plane learns that this isn’t the case, it sets out to assign the job and resolve the discrepancy.
A note on terminology.
So what about the master role? At the time of writing (as of release 1.24), it is interchangeable with control-plane. “Master” was the original term and is currently retained to maintain integrations between components that use the label, but the Kubernetes project plans to phase out the use of the word in this context. Eventually, the get nodes command above will only return control-plane for the node role.
This change reflects an ongoing conversation about the suitability of the term “master” in the tech industry and broader culture; many technologies are moving away from the use of “master” terminology just as they moved away from the use of “slave” metaphors several years ago. GitHub, for example, now encourages defining a “main” branch rather than a “master” branch.
The important thing to know when learning Kubernetes is that many third-party resources will discuss master nodes, though the term is no longer used in the Kubernetes documentation. These older resources are referring to nodes with the control-plane role, which we can think of as members of a cluster’s leadership committee. From here on out, we’ll use “control plane” to refer to this role.
Ultimately, the control plane is a group of components that work together to make the actual state of the cluster match its spec. It responds to unexpected events out there in the real world (like a service going down), and it takes onboard any changes to the spec and assigns resources accordingly.
So what are these control plane components?
kube-apiserver: Last lesson, we said that every interaction with the cluster from tools like kubectl or Lens is mediated by the Kubernetes API. The API server exposes that API. The API server is the hub at the center of activity on the cluster, and the only control plane component that communicates directly with nodes running workloads. It also mediates communications between the various elements of the control plane.
kube-scheduler: Put simply, the scheduler assigns work. When we tell the API server that we want to run a workload, the API server passes that request to the scheduler. The scheduler, in turn, consults with the API server to check the cluster status and then matches the new job to a node that meets the relevant resource requirements—whether that means hardware specifications or policy constraints.
etcd: By default, the Kubernetes cluster runs on an assumption of ephemerality: any node and any workload may be spun up or stopped at any moment and replaced with an identical instance. The processes in the cluster are meant to match a specification, but they’re not expected to persist. This is a philosophy of statelessness, and it resembles the operational assumptions of containers themselves. But even if you’re running entirely stateless apps on your cluster, you will need to save and persist configuration and state data for the cluster, and etcd is the default means of doing so. It's a key-value store that may be located inside the cluster or externally. Only the API server communicates directly with etcd. Note that etcd may be used outside the context of Kubernetes as well; it’s ultimately designed to serve as a distributed data store for relatively small amounts of data.
kube-controller-manager and cloud-controller-manager are the watchdogs: they constantly monitor the state of the cluster, compare it to the spec, and initiate changes if the state and spec don’t match. The kube-controller-manager focuses on the upkeep of workloads and resources within the cluster, while the cloud-controller-manager is essentially a translator who speaks the language of your cloud provider–dedicated to coordinating resources from your cloud infrastructure. The cloud-controller-manager is an optional component designed for clusters deployed on the cloud.
It’s tempting to think of the control plane as one or more “boss” nodes—that’s essentially true, but it’s a bit of a simplification that obscures important details. For example, etcd may be integrated into a control plane node or hosted externally. And as we’ve seen, a control plane node includes all of the components of a worker node. Typically, components of the control plane are initially installed on a single machine that doesn’t run container workloads…but that’s not a necessary or optimal configuration for every situation.
We can visualize a control plane node like this:

Kubernetes is a distributed system designed in large part for resiliency. But as you can imagine, the control plane could become a single point of failure, especially if it is consolidated on one machine. For this reason, the system offers a “High Availability” configuration, which is the recommended approach for production environments. A High Availability (or HA) cluster will include multiple replicas of the control plane node.
While one of the control plane nodes is the primary cluster manager, the replicas work constantly to remain in sync—and a load balancer can apportion traffic between the various replicas of the API server as needed. Similarly, if duplicates of etcd are sitting on multiple control plane nodes (or an external host), they form a collective that runs its own consensus mechanism to ensure uniformity between the members. These measures ensure that if a control plane node goes down, there are replicas available to pick up the slack.
Kubernetes architectural patterns
Before we move on, let’s pause and take stock:
A cluster is made up of one or more nodes.
Any node can run container workloads.
At least one node also has the components and role to act as the control plane and manage the cluster.
A cluster configured for High Availability (that is, production-grade resilience) includes replicas of all control plane components.
Now, with all of these takeaways in place, let’s look at the big picture. What are the major architectural patterns for a Kubernetes cluster?
Single node: This pattern is what we have running right now via Minikube—a single cluster that fulfills the role of the control plane and runs any workloads we wish to run. This node walks and chews bubblegum at the same time: great for learning and development, but not suited for most production uses.
Multiple nodes with a single node control plane: If we were to connect another node to our cluster as a dedicated worker node, then we would have a cluster with clear separation of responsibilities…but also a single point of failure in the control plane node.
Multiple nodes with High Availability: When control plane components are replicated across multiple nodes, a cluster can achieve high levels of resiliency through strategic redundancy.
For each of the models above, there are two major sub-variants: you might include the etcd data store on the control plane node(s)—a model called “stacked etcd”—or you might host etcd externally. High Availability configurations are possible with both of these approaches to the data store.

As we’ve established, we’re currently working with a single-node cluster. Let’s get a little more information about that node and see how it correlates with what we’ve learned about Kubernetes architecture:
% kubectl describe node minikubeThis command will give us a good deal of information on our node. Read through the output and look for references to the components we’ve discussed. A few sections to note:
…
System Info:
Machine ID: 8de776e053e140d6a14c2d2def3d6bb8
System UUID: 45bc9478-1425-44bd-a441-bfe282c0ce3e
Boot ID: fbdac8bf-80eb-4939-86f1-fcf792c9468f
Kernel Version: 5.10.76-linuxkit
OS Image: Ubuntu 20.04.2 LTS
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.12
Kubelet Version: v1.23.1
Kube-Proxy Version: v1.23.1
…My Minikube cluster is running on a container, so the information on my system refers to those details. Here we also find version numbers for our universal node components like the container runtime, kubelet, and kube-proxy.
Further down, we can find information on node resource usage. Note some of the entries in the “Non-terminated Pods” list:
Namespace Name CPU Requests CPU Limits Memory Requests
--------- ---- ------------ ---------- ---------------
…
kube-system etcd-minikube 100m (2%) 0 (0%) 100Mi (1%)
kube-system kube-apiserver-minikube 250m (6%) 0 (0%) 0 (0%)
kube-system kube-controller-manager-minikube 200m (5%) 0 (0%) 0 (0%)
kube-system kube-proxy-9rjzk 0 (0%) 0 (0%) 0 (0%)
kube-system kube-scheduler-minikube 100m (2%) 0 (0%) 0 (0%)
… Here we find a number of familiar faces: our instances of the API server, etcd, the scheduler, and the controller manager—the whole control plane team—as well as kube-proxy.
But wait—what’s a pod? That’s a question for our next lesson. Now that we understand the architecture of a Kubernetes cluster, next time we’ll take a look at the core abstractions that govern activity on the cluster: Kubernetes Objects.





